意思決定の精度を高めるためのビッグデータ活用、データで導く施策の成否
2014年WAB宣言「Big Data 2.0 ~オンラインデータがビジネスを変える~」を受け、WABフォーラムの第一部では、ビッグデータの実践的な活用方法について、APT社の及川直彦氏が講演。データドリブンによる意思決定の精度向上や予測分析の実例が明かされた。
ビッグデータ議論で見逃しがちな意思決定の精度向上

シニアバイスプレジデント
及川 直彦氏
フォーラムの第一部は、予測分析ソフトウェア大手APT社の及川直彦氏が登壇し、「ビッグデータを活用したマーケティング戦略 予測分析による収益改善機会の探索と意思決定」という講演を行った。
まず「ビッグデータとは何か」という話題に触れた及川氏は、アンドリュー・マカフィーとエリック・ブリニョルフソンの著書『ビッグデータで経営はどう変わるか』を引用して説明する。ビッグデータは、データの分析から知見を引き出して事業上の優位につなげるという点で、従来のデータ分析と変わらないが、取り扱う「Volume:データの量」「Velocity:鮮度」「Variety:多様性」の違いによる新たな可能性に着目をした議論だという。
しかし、この3つの違いが及川氏個人としては非常にわかりにくい定義となっており、このわかりにくさがビッグデータに対して多様な解釈を生んでいるとし、「Volume、Velocity、VarietyというようにVで言葉をそろえても、日本人にはあまり関係がない」と話す。この3つのVから、これまでにない新しいデータを使うものとしてビッグデータが語られ、定義をわかりづらくしているというのだ。
3つのV、Volume(量)・Velocity(鮮度)・Variety(多様性)が
ビッグデータの定義をわかりづらくしている
そこで及川氏は、他のビッグデータの例として、マッキンゼー・アンド・カンパニーの2011年の小売業に対する戦略コンサルティングの資料を示す。まず、現在のビッグデータは、以下のテーマで活発に議論されているという。
- クロスセリング(レコメンデーション):的確な推奨で再購買・追加購買を拡大
- ロケーション・ベースド・マーケティング:位置情報で店舗の近隣にいる顧客の来店を誘導
- センチメント分析:ソーシャル・メディア上の発言を活用し着想
- マルチチャネルの顧客体験の向上:オンライン・店舗・カタログの配分や連携を最適化
- Webベース・マーケット:AmazonなどWebベースの小売サービスの台頭
だが、マッキンゼーの資料では上記以外のマーケティング機能として、「インストアの行動分析」「顧客のマイクロ・セグメンテーション」といったものや、「マーチャンダイジング機能」「オペレーション機能」「サプライチェーン機能」などでもビッグデータを活用した改善が可能であり、新たなビジネスモデルを拡大できる可能性があるとしている。
上記の分野でのみビッグデータの議論がなされているのは、ビッグデータを活用することによる「意思決定の精度の向上」よりも「施策の選択肢の広がり」に議論が偏っているのではないか、と及川氏は話し、「議論が偏ってはいるが、新しい武器としてのビッグデータのほうがおもしろい。今回は意思決定の精度の向上におけるビッグデータ活用について話したい
」と説明する。
ビッグデータは施策の選択肢を広げるだけでなく、
意思決定の精度向上にも活用できる
続いて、ビッグデータ活用の例として「Googleインフルトレンド」を紹介した及川氏は、Googleが検索語5,000万語の中から特定の検索語45語を洗い出してインフルエンザ流行予測を行ったことを示す。マーケッターのようにデータの因果関係を考えて仮説を立てるのではなく、機械学習的にランダムに相関関係を探っていると説明する。
ただし、分析方法には得手不得手もある。
仮説を立てるときには因果関係は絶対欠かせない。因果関係がわからなければ、アイデアは生まれないというのが私の立場。ただし、アイデアを生むための因果関係を作るときに使った回帰モデルを効果検証にまで使うのは間違っているかもしれない。
つまり、“アイデアを発想に広げる分析”と、“広げた発想を検証してどのくらい投資するのかという意思決定のため分析”は、質が違う。どのくらい投資するかを決める場合は、因果関係ではなく、ドライな相関関係を重視した方がむしろよい場面が多いのではないか(及川氏)
人間がアイデアを着想し、実験や分析は機械的に行う
「ビッグデータを活用した意思決定とは」という話題に移る及川氏は、「アイデアの着想」―「実験・分析」―「理解・決定」の「Test&Learnのサイクル」を示す。このなかで、アイデアは因果関係の仮説から人間が出すもので、統計的に有意かどうかはこの段階で心配する必要はなく、自由に発想したほうがよい。それらの発想から出てきたものを試すときに、統計的有意を意識すればよい、というのが及川氏の考え方だ。
続けて「施策の投入前と投入後に販売額にどのような影響があるかを話したい」と述べる及川氏は、予測分析で必ず出てくる「リフト」と「ターゲティング」について説明する。

たとえば、これまで20億円だった利益が、ある施策によって2,000万円増えた場合は「1%のリフト」ということになる。このように、リフトが0%よりも高い有効な施策を特定し、その施策ごとにターゲティングを行うことができれば、利益を着実に改善できる。
また、DMをすべての顧客に対して送るのではなく、ターゲティングによって絞り込んで反応率を上げれば、全体の売上自体は下がったとしても、DMのコストを大幅に削減できるので利益のリフトを高くできる。「予測分析によってリフトがクリアになる。また、施策を投入するときに反応が特に良いセグメントを見極めてターゲティングを行うことによって、費用対効果が高まる
」と及川氏は説明する。
ある程度の誤差が許容され、シビアな精度が求められない分析では回帰モデルを使ってよいが、数%で黒字か赤字かが分かれてしまうようなシビアな分析では、回帰モデルによる予測分析には限界がある及川氏は説明する。こうした場合には、実験に基づく予測分析の方がより高い精度と経営へのインパクトを期待できるという。
しかし、従来型の実験計画法では、さまざまな要因によって売上のベースが上下してしまう「ノイズ」があり、施策によって売上が上がっても、ベースが上がっていたのでは施策の効果が出ているとはいえない。また、施策を投入して売上が上がらなくても、たまたまベースが下がり続ける時期であった場合は広告が下支えしたことになり、施策の効果として認められるだろう。誤った判断をしないためには、他の要因によるノイズを取り除く必要があるのだ。
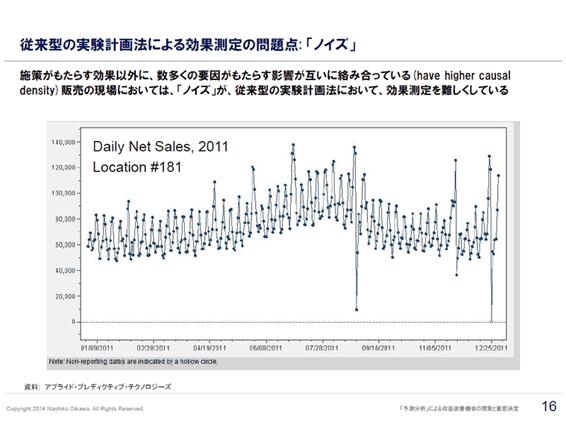
効果測定におけるノイズを排除しなくては、
施策の効果を正しく判断することはできない
これを解決するためには、よく似た売上カーブを描いている複数の店舗を選び、同期間に施策を行うテスト店舗と、比較対象とするコントロール店舗に分けて実験する方法がある。しかし、適切なテスト店とコントロール店を選ぶには、ノイズを排除するために、店舗の立地条件や顧客の性年齢層などの条件を揃えなくてはならない。従来の方法では、人間の勘や職人技でテスト店とコントロール店を選ぶことになる、とする及川氏は「このような場合にこそ、人間の力ではなく、コンピュータを使えばよいのではないか
」と話す。
実際にAPTでは、ビッグデータを活用してノイズを除去するための独自ソフトを有しており、パターン認識によって、POSデータを過去にさかのぼり、よく似たカーブを描く店舗を見つけることができるという。従来であれば、A店舗とB店舗は似た条件のはずだと、仮説をもとに実験計画を立てるものだが、機械的に同条件の店舗を選び出している。
ビッグデータによる意思決定
その他の事例として、及川氏はビッグデータ選挙と呼ばれた、2012年米国大統領選挙におけるオバマ陣営の取り組みを紹介する。同選挙では、施策ごとに効果が出るかどうかを分ける変数を機械学習で見つけ、費用対効果の高いセグメンテーションが行われたという。
たとえば、選挙戦における有権者の説得モデルを構築し、激戦州を避け、働きかけるべき州を導き出し、「説得がされやすい」ターゲットにスタッフが接触していった。「ここにはペルソナという概念はなく、施策そのものが効くか効かないかだけをドライに考え、セグメンテーションを徹底的にやっている
」と及川氏は話す。
続いて、外食チェーン店においてセットメニューの投入でどれだけ売上を上げられるか、APTの分析ソフト「Test&Learn」を用いた事例が示された。従来の実験計画法では、収益に貢献できないと考えられていた新しいバリューメニューが、APTのコントロール群手法によってターゲティングを行えば効果があると予測され、実際に新メニューを投入することで売上を伸ばすことができたという。

新メニューのアイディアが出た後、それを導入するべきかどうかを意思決定するときには、人間が因果関係に基づいて推測するのではなく、ある程度機械に任せながら実験を展開してしまえばよい。ビッグデータは、人間がいろいろと考えた施策の白黒をハッキリさせて絞り込み、さらに利益を上げられるように磨きこんでいくことができる(及川氏)
及川氏は最後にこのように話し、第一部の講演を終えた。

オリジナル記事はこちら:「意思決定の精度を高めるためのビッグデータ活用、データで導く施策の成否」2014年3月20日開催 第28回WABフォーラムレポート(1)





必見! Facebookいいね! 人気記事
最近(過去90日間)の記事で、Facebookの「いいね!」が多かった記事をお見逃し無く。
第3回 Looker Studio活用講座 ~サッと欲しいデータが見える!GA4とサーチコンソールで効率レポート術
 1,128 いいね!
1,128 いいね!【広告主・マーケター限定】8/26 オンライン開催 デジタルマーケターズサミット 2025 Summer
741 いいね!Web担 編集後記 2025年6月
441 いいね!はじめてのGoogle広告入門講座 P-MAXキャンペーンやAIを活用! 予算の無駄をなくす「入札戦略」を学ぶ
409 いいね!ChatGPT一強に変化の兆し? 生成AIの伸び率トップは「Gemini」【日本リサーチセンター調べ】
218 いいね!<第1回>無料ツールで始める“一人でできる”「Webサイト改善講座」~GA4・Clarity・サーチコンソール徹底活用【7時間集中講義】
170 いいね!参加してよかったエンジニアサマーインターンシップ、初めて1位を獲得した有名企業は?【サポーターズ調べ】
118 いいね!

ソーシャルもやってます!