NTTドコモがLLMと企業データから生成したユーザーモデルで行動を予測する技術を開発
施策の事前シミュレーションで商品の企画や需要の予測が効果的に、LLMの課題を解決
3/24 7:01 マーケティング/広告 | AI | 便利ツール/サービス
NTTドコモは、大規模言語モデル(LLM)と企業が保有する固有データから生成したユーザーモデルへのヒアリングによって実際のユーザーの行動や選択を予測する技術と基盤を開発した、と3月21日発表した。小売店などを展開する企業は、事前にさまざまなマーケティング施策をシミュレーションすることで、新商品の企画や需要の予測が効果的にできるようになる。
LLMは、性別、年齢層など一般的な属性や職業などのプロファイル情報を与えて質問すると、それに基づいた回答が容易に得られる一方、回答が一般的だったり、過去のデータに含まれる単語に影響されたりする。さらに、学習データセットに依存する知識のかたより(バイアス)で期待した回答が得られない課題があった。今回開発した技術はこうした問題を解決する。
この技術は、バイアスの影響を抑えるよう学習したパラメータ(属性ベクトル)でユーザーモデルを生成するなどしてバイアスを取り除く。企業固有の匿名化したデータをさらに多段階のクラスタリング(集団化)で統計化した情報から出力データセットを生成し、属性ベクトルの抽出に利用。LLMに属性ベクトルを加えるため性格、価値観など多様な属性が付与できる。

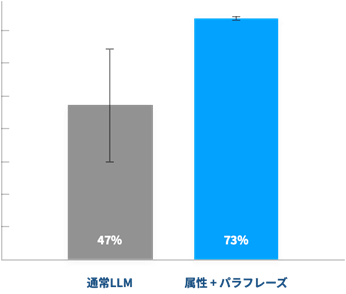
ドコモは、独自に実施した味覚に関する2万人のアンケートを使い、設問に対して平均に近い回答が生成できるか評価実験を行って技術の効果を検証した。その結果、通常のLLMは正答率が最小30%、最大65%と不安定だったが、属性ベクトルを与えて質問順序の入れ替えなどをしたこの技術の正答率は73%だった。ドコモは自社サービスへの技術の適用を検討する。



関連記事:


これは広告です


これは広告です
必見! Facebookいいね! 人気記事
最近(過去90日間)の記事で、Facebookの「いいね!」が多かった記事をお見逃し無く。

ソーシャルもやってます!