機械学習(AI)入門 ―― SEO担当者も2020年には知っておきたい基本のキ
デジタルの世界で働いていれば、だれにとっても機械学習(ML、Machine Learning)の重要性は増すばかりだ。とはいえ「機械学習」と聞くと、手を出しにくいテーマのように感じることも多いだろう。
しかし、そんな風に思う必要はない。SEOタスクの自動化という点で、機械学習がもたらす競争力を活用しない手はない。
頭をテクニカルSEOに切り替えて、メモを取る準備をしよう。今回のホワイトボード・フライデーでは、ブリトニー・ミュラーが機械学習の基本について説明してくれる。
Mozファンのみんな、こんにちは。ホワイトボード・フライデーにようこそ。今回は、機械学習についてあれこれ話そうと思う。
知っている人も多いだろうけど、これは私が特に情熱を持っているテーマで、話題にするのも大好きだ。そのため、これを機にさらに掘り下げてみる人が出てくることを願っている。というのも、機械学習は、私たちの分野で長年にわたって起こってきたことの中でも特に強力なものだからだ。
機械学習とは
簡単に一言で説明すると、機械学習とは実際には人工知能(AI)のサブセット(下位概念)だ。実際にはまだAIは実現していないとする人もいるだろう。だが、機械学習はAI全体の1つの面に過ぎない。

従来のプログラミング
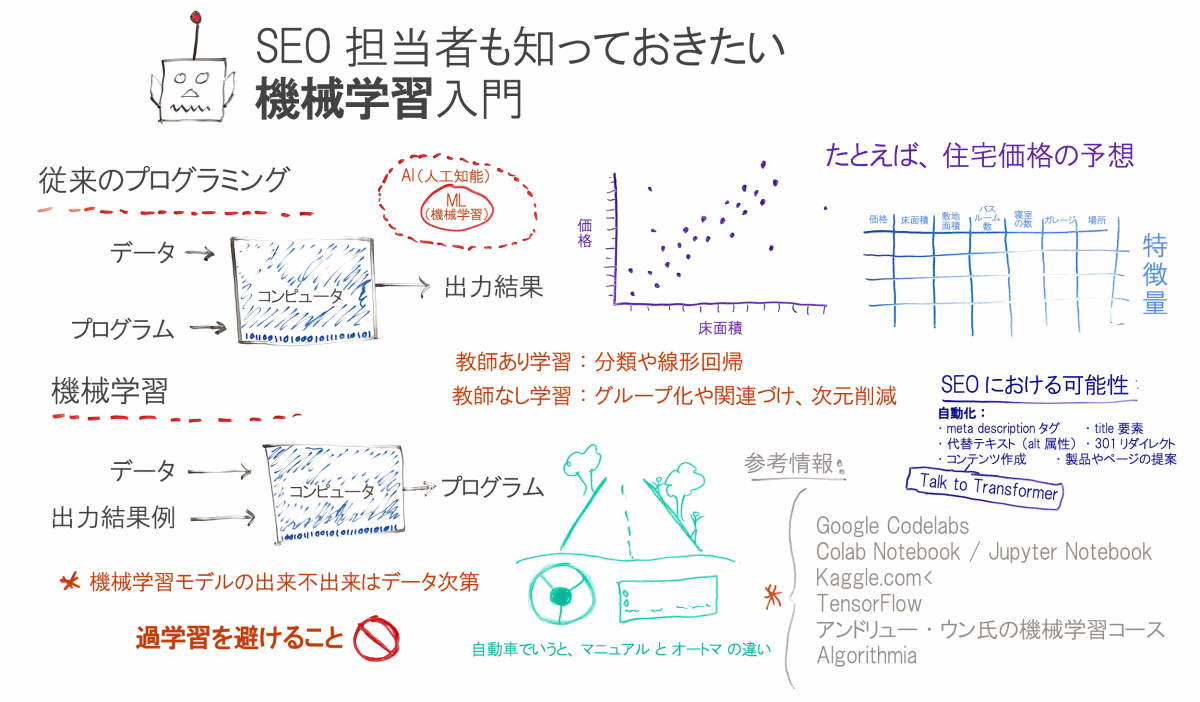
機械学習について考える最適な方法は、従来のプログラミングと比較することだ。
従来のプログラミングでは、データとプログラムをコンピュータに入力すると、結果が出力される。出力されるのはウェブページでも、オンラインで作成した計算機でも、何でも構わない。
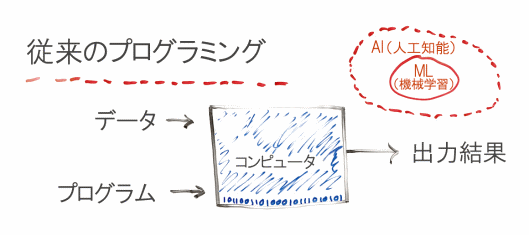
機械学習
機械学習ではどうするのかと言えば、データと必要な出力結果をコンピュータに入力するとプログラムが生成される。この生成されるプログラムが「機械学習モデル」と呼ばれるものだ。
従来のプログラミングとは逆の形だが、これが非常にうまく機能する。機械学習は、次の2つのタイプに大別される。
教師あり学習では、基本的にはラベル付けしたデータをモデルに与える。
教師なし学習では、プログラムにデータを与え、プログラム自身にデータポイント同士のグループ化や関連づけをさせる。
この2タイプのなかでは、教師あり学習のほうがやや一般的だ。「分類」「線形回帰」「画像認識」などでよく見られる。
機械学習を考える視点として、こうしたデータをすべてモデルに入力しなければならない点。データは機械学習の最大の部分を占める。機械学習が車だとしたら、データは燃料だと言う人は多い。
これを理解するのは非常に重要だ。なぜなら、適切な種類のデータをモデルに与えなければ、期待通りの出力は得られないからだ。
機械学習モデルの例
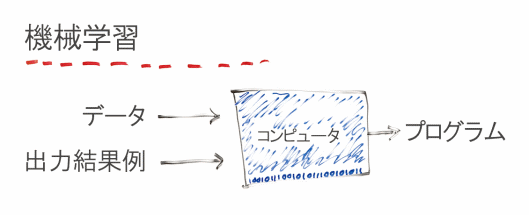
ここで1つの例を見てみよう。住宅のさまざまな情報をもとに、住宅価格を予想するモデルだ。
住宅価格を予想する機械学習モデルを構築したい場合は、まずわかっている既存の情報を集める。たとえば次のようなものが考えられるが、挙げればきりがない。
- 現在の価格
- 床面積
- 敷地面積
- バスルームの数
- 寝室の数
これらは特徴量(feature)とも呼ばれる。機械学習は、こうしたデータをもとに、情報の関連性を理解して、将来の住宅価格を最も的確に予想するモデルを生み出す。
これらの機械学習モデルで最も基本的な手法は、線形回帰だ。データの入力について考えると、価格と面積だけを入力した場合、データはこのような形になる。
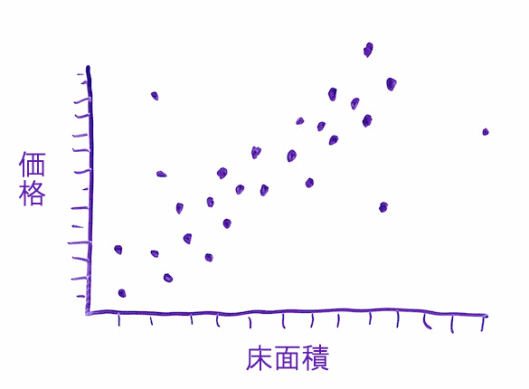
面積が大きくなるにつれて、価格も高くなっていくのがわかる。モデルは経時的にこうしたデータを見て、最も正確な将来予測が立てられるように、データのなかを通る最も滑らかな線を見つけようとする。
このときに発生すると困るのは、データポイントを1つひとつ結んで、ジグザグの線を描いて「これがパターンだ」とみなすことだ。これは過学習(過剰適合)とも呼ばれる。なぜなら、これは新しいデータポイントにはうまく適合しないからだ。データセットに合わせて計算するあまり、将来を正確に予想できないモデルになっては困る。

これに対処する方法としては、損失関数を使う。少し深入りしすぎるかもしないが、これは、線がどれくらい適合しているかを測る方法だ。では、次に行こう。
SEOにおける機械学習の可能性
SEOにおける可能性には、どのようなものがあるだろう? SEOの分野で、機械学習をどのように活用できるだろうか?
meta descriptionタグの自動生成
すでに行われている方法はいくつかある。ページのコンテンツを見て、文章を要約する機械学習モデルを利用することで、meta descriptionタグを自動生成できる。このやり方はコンテンツを文字通り要約し、meta descriptionタグにふさわしい長さに短縮してくれる。実に見事だ。
title要素の自動生成
同様にtitle要素も自動化できるが、主要なページには利用しないことを推奨する。これは完璧な方法ではない。ただし、ウェブサイトが巨大で、膨大な数のページがある場合には、作業がずいぶん楽になるだろう。まずはそうした大規模なウェブサイトの分野で使ってみるのは非常に興味深い。
画像の代替テキストの自動生成
画像の代替テキスト(alt属性)を自動生成することもできる。これらのモデルが、画像の内容を本当によく理解できるようになってきた。
301リダイレクトの自動化
301リダイレクトについては、すでにポール・シャピロ氏が素晴らしい解説と基本的な手順について記事を書いている。
コンテンツ作成の自動化
「コンテンツ作成」と聞いて心配になる人や、逆に現時点でこれらのモデルにまともなコンテンツが作成できるのか疑わしいという人は、ぜひTalk to Transformerをチェックしてみてほしい。
これは、イーロン・マスク氏らが設立したOpenAIの簡易版だ。
※Web担編注 Talk to Transformerは、テキストエリアに何らかの文章の一部を入力して「COMPLETE TEXT」ボタンを押すと、続きの文章を自動生成する。日本語では正しく動作しないが、英語の文章の一部を入れてボタンを押してみるといいだろう。
驚くほど素晴らしく、この簡易モデルから作成されたコンテンツにしては優れているという点で、少し恐ろしさを覚える。したがって、将来どころかすでに現在でも、コンテンツ作成が可能なのは確かだ。
製品やページの提案の自動化
さらには、製品やページの提案(レコメンド)も可能だ。
機械学習は、今後ますます進化するばかりだ。サイトを訪れるユーザー一人ひとりに合わせたコンテンツやユーザー体験を提供できることを想像してみてほしい。高度にパーソナライズされたコンテンツ、高度にパーソナライズされた体験だ。今後のことを考えると、本当にエキサイティングだ。
参考リソース
ぜひチェックしてほしいリソースをいくつか紹介しよう。
Google Codelabsは、段階を追って説明してくれるので、私のお気に入りの1つだ。Google Codelabsにアクセスしたら、TensorFlowまたはMachine Learningでフィルタリングすると、使えそうな例が表示される。
Colab NotebookやJupyter Notebookを使えば、自分でやってみたいあらゆる機械学習ができるだろう。
Kaggle.comは、データサイエンス分野のコンテストのことがわかるいちばんのリソースだ。どのような例があるか、機械学習が現在、どのように使われているかを実際に確認できる。
米運輸保安庁(TSA)が監視カメラの映像から潜在的な脅威を予想するモデルを開発するため、データサイエンスチームに100万ドル以上を投じたことなどがわかる。
こういったことは、ものすごいスピードで非常におもしろくなってくる。また、この分野では、今後非常に危険なモデルを回避するために、多様性の検討やその受け入れも重要だ。これが考慮すべき問題なのは間違いない。
TensorFlowは素晴らしいリソースだ。これはグーグルが公開しているもので、同社の機械学習モデルの多くはこれを基にしている。グーグルは本当に素晴らしいJavaScriptプラットフォームを持っているので、色々試してみることができる。
アンドリュー・ウン氏は、実に優れた機械学習のコースを提供している。ぜひチェックしてみてほしい。
Algorithmiaは、各種モデルのワンストップサービスのようなものだ。機械学習に足を踏み入れたいわけではなく、たとえば要約モデルや特定の種類のモデルが必要なだけの場合には、ここでそれを見つけて、プラグアンドプレイのようなことができるかもしれない。

いろいろと調べてみると非常に興味深いし、楽しい。最後に、機械学習モデルの出来不出来はデータ次第であることを指摘したい。これはどれだけ口で説明しても説明し足りない。多くの機械学習やデータサイエンティストには、データのクリーニングや解析がすべてであり、それがこの領域の仕事の大部分を占めている。
その点を認識することが重要だ。これで、機械学習の基本は以上となる。見てくれてありがとう。近いうちにまたお会いできるのを楽しみにしている。さようなら。





この記事は、Moz Blog に掲載された以下の記事を、Mozの許諾を得て日本語化したものです。

原文: 「Machine Learning 101 - Whiteboard Friday」 by Britney Muller (2019/10/25)
必見! Facebookいいね! 人気記事
最近(過去90日間)の記事で、Facebookの「いいね!」が多かった記事をお見逃し無く。

ソーシャルもやってます!