論争や心痛を増やし、コンサルティングの時間も多くかかる問題(少なくとも最近の)といえば、それは複製コンテンツ(Duplicate Content、重複コンテンツともいう)だね。
最新の検索エンジンにおけるこの災いは、標準的なライセンス供与のかなり温和な部分と、時折見かける盗用に起因するものなんだ。この5年間で、コンテンツが欲しくてたまらないスパム業者は、正当な情報源から(多数の複雑な工程を通じて)コンテンツを抜き取り、ロングテールの検索トラフィックを得たり、コンテンツ連動広告に役立つことを期待し(ほかにもさまざまな不正目的のために)、抜き取ったコンテンツの語句をごちゃ混ぜにして、その文章を自分のページで使い回すといった行為を始めたんだ。こうした行為に対して、今は多くの批判が集まっている。
こうして僕らは、「複製コンテンツ問題」と「複製コンテンツによって受ける検索エンジンでのペナルティ」の世界に直面している。幸いなことに、頼りになるGooglebotのイラストと僕がいるわけだし、こうした混乱状態を多少なりとも解消する手助けをしてみたい。まず素敵な挿絵を見る前に、いくつか定義を説明しておこう。
ユニークコンテンツ――人間が書いたもので、ウェブ上に存在するほかの文字、記号、単語の組み合わせとは完全に異なり、明らかにコンピュータのテキスト処理アルゴリズム(マルコフ連鎖を使った常識はずれのスパムツールなど)によって処理されていないもの。
スニペット――複製と再利用の対象になる格言のような小規模なコンテンツ。これらは、特にユニークコンテンツの比率が高い大量の文書内にある場合、検索エンジンにとってほとんど問題にならない。
複製コンテンツ問題――通常僕がこの言葉を使う場合、ウェブサイトがペナルティを課される危険を持つ複製コンテンツではなく、単に既存のページをコピーし、検索エンジンがインデックス化する際に、どちらか選ばざるを得なくなくことを指している。
複製コンテンツのペナルティ――僕が「ペナルティ」という場合、検索エンジンが実施する事柄で、単にページをインデックスから外すよりも深刻なことだけを指している。
さて、Googleがウェブ上で複製コンテンツを見つけ出すプロセスを見ていこう。下記の例で僕はいくつか仮定を挿んでいる。
テキストを含むページが、複製コンテンツであると仮定する(挿絵ではスニペットだがページ全体が複製であるとする)。
複製コンテンツを含むページは、それぞれ異なるドメイン上にあるとする。
以下に示した手順は、できるだけ簡潔明瞭にするため単純化している。これは、Googleの振る舞いを正確に示すものじゃない(でもその要点は、かなりうまく示している)。


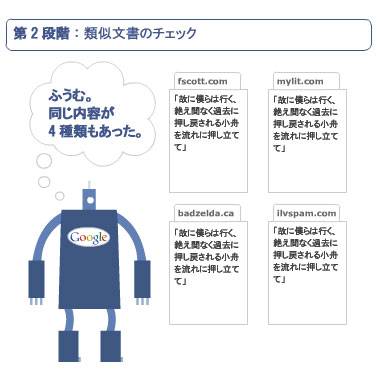
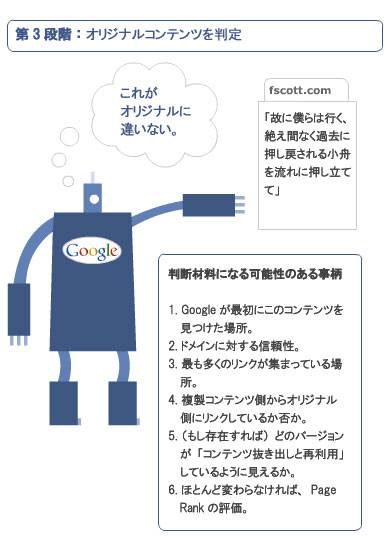

複製コンテンツに関して、言っておくべきことがまだいくつかある。これらの多くは、複製コンテンツ問題になじみのないウェブマスターにとって、障害となるものだ。
残念なことに、こうした人たちに対する公式のガイドラインを、検索エンジンは公開していない(まあそのおかげで、僕らみたいなのが職にありつけるんだと思うけど)。こうした初心者たちと、しょっちゅう電話で話したりフォーラムで会ったりして、こんな話を書き出してみた。
コードとテキストの比率:もし自分の作ったページのコード量が膨大で、独自のHTML要素が非常に少なかったらどうなる? Googleはこうしたページをすべて、互いに複製したものと見なすんだろうか?
そんなことはない。シカゴでVanessaが僕らのビデオの中ではっきりと言ってたように、Googleはコードに関心がなく、ページの中のコンテンツに興味を示す。
ユニークコンテンツとナビゲーション要素の比率:サイト内の全ページに大きなナビゲーションバーがあって、ヘッダーやフッターなんかの量は多いけれど、コンテンツがほんのちょっとだったら、Googleはこれらのページを複製コンテンツと見なすだろうか?
これも違う。Google(そしてYahoo!やMSN)は経験豊富だ。検索エンジンはウェブサイトのレイアウトを熟知していて、すべての(あるいはほとんどの)ページにある常設の構成物が、極めて当たり前の存在かどうか見分ける。その代わりに検索エンジンは、各ページの「独自」部分に注意を払い、多くの場合はそれ以外の部分をほとんど見ない。
ライセンスを得たコンテンツ:複製コンテンツの問題を回避したいけれど、他所のウェブサイトから掲載ライセンスを得たコンテンツを、自分のサイトに来た人たちに見せたい場合、どうしたら良いんだろう?
<meta name = "robots" content="noindex, follow">というメタタグを置こう。このタグをページの頭に書けば、検索エンジンは該当のコンテンツがそのサイトを利するものじゃないと知ることができる。このタグを置いても、人間がアクセスしたり、リンクを張るのに問題は起きないし、ページ内のリンクも検索エンジンに対する有効性を保てるから、これが最良の方法だ(僕の考えではね)。
コンテンツ盗用:自分のコンテンツをコピーしているサイトを見つけたら、どうやって解決したら良いのかな?
自分のページに関係するクエリで、盗用サイトのページを見つけても、それが補足インデックスの中とか、自分のページより下位だったら、僕の場合大体は無視しちゃう。もし、僕らがウェブ上にあるSEOmozのあらゆるコピーに対して戦いを挑むとしたら、少なくとも毎週40時間の仕事を抱えることになるだろうね。ただまあ、SEOmozは僕らのコンテンツを掲載する中で、上位ランクを得るのに十分な強さのリンクを持つ唯一のドメインだし、検索エンジンもSEOmozに対して、高品質で関連性と価値の高いコンテンツを掲載するサイトだと信頼を置いているのは、幸いと言うべきなんだろう。
一方、もし自分のサイトが比較的新しい場合や、あまり被リンクがなく、コンテンツ盗用サイトの方が自分よりも上位ランクにいる(あるいは、強力なサイト持つ誰かがコンテンツを盗用している)場合には、いくつかの対処法がある。
1つの選択肢は、Google、Yahoo!、あるいはMSNに、デジタルミレニアム著作権法(DMCA)違反の報告を提出することだ。もう1つの方法は、問題のウェブサイトに対し、告訴(もしくは告訴するぞという警告を)すること。DMCA違反通報が効果を発揮するまで何ヶ月も時間がかかるので、盗用サイトの所有者が同じ国にいるなら、おそらく後者の方が第1手としてはましだろう(弁護士の書いた文書が相手に届くまで、僕はいつも友好的な態度を崩さないよう努めているよ)。
複製コンテンツの割合:ページ内で複製コンテンツの割合がどのくらい大きくなると、ペナルティを喰らったり問題になったりするんだろう?
そうね、22.45%だね。いやいや、まじめに言うと、検索エンジンはこういう情報を絶対公開しないだろう。もしそんなことをすれば、複製コンテンツ問題の防止手段を損ねることになってしまうからね。各検索エンジンではその比率が定期的に変動していて、複製コンテンツかどうか調べるときに、ただ直接比較する以上のことを行っているのは、ほぼ間違いない。もしこの疑問に対する答えが本当に欲しいなら、多分クラッカーみたいな真似をするしかないよ。
ペナルティか否か:複製コンテンツがあるせいでペナルティを喰らったのか、それとも単にインデックスから外れた(あるいは補足インデックスに追いやられた)だけなのか、どうすれば判断できるんだろう?
複製コンテンツの掲載期間が相当長期にならないと、検索エンジンはペナルティを課さない。ただし僕の知る限り、たとえ真っ当なブランドのドメインだろうと、ペナルティは喰らう。ペナルティは、十分なユニークコンテンツがないのに、他所のドメインから無数のページをコピーし始めると発生する。新規サイトや所有者が変わったばかりのサイトなどは、特に注意が必要だ。しかし、ペナルティを受けたとか、多数のページが補足インデックスに入ったとか、そんなことを気にするよりも、これまで説明してきた問題を修正するよう強く薦めるよ。
複製コンテンツ問題に関する意見や、僕が見逃したり勘違いしているところがあれば、是非教えて欲しい。
追記。僕のお絵描き技術が向上したおかげで、Googlebotが格好良くなったね。貧相なGooglebotが気の毒で、翌朝に電話会議を控えた深夜にもかかわらず、手直しせずにいられなかったんだ。




この記事は、Daily SEOmoz Blog に掲載された以下の記事を日本語訳したものです。
原文:「The Illustrated Guide to Duplicate Content in the Search Engines」 by randfish (2007/03/12 03:08 PST)
必見! Facebookいいね! 人気記事
最近(過去90日間)の記事で、Facebookの「いいね!」が多かった記事をお見逃し無く。

ソーシャルもやってます!