テクニカルSEOに効く! Webサーバーの生ログ解析は知っておいて損はない(基礎編)
テクニカルSEOに効く「生ログ解析」を、あなたは知っているだろうか。クローラの挙動を把握して、よりサイトを効率良くクロールしてもらったり、エラーを見つけたり、クロールバジェットを把握したり――そうしたことをするには、Webサーバーが保存するログファイルを解析するしかない。その方法について、わかりやすく解説する。
米国では一時期、夜の10時か11時になると、「あなたは今、自分の子供がどこにいるか、わかっていますか?」と問いかける公共広告が、テレビで頻繁に流れていた。
これと同じように、僕は問いかけよう。
夜10時、あなたは今、自分のWebサイトの生ログがどこにあるかわかっているだろうか?
というのも、生ログ解析がいかに重要で、周知させる価値があるかを強く訴えたいからだ。
自社のテクニカルSEOやオンページSEOが貧弱なら、Webサイトの生ログより重要なものはないと言ってもいい。テクニカルSEOは、検索エンジンにWebサイトをクロール・解析・インデックス化してもらい、マーケティング活動が始まる時点ではすでに適切な検索順位がついているようにするための要となる。
何よりも覚えておいてほしいのは、検索エンジンがWebサイトをどのようにクロールしているかについて、唯一、100%正確なデータを提供してくれるのが生ログファイルだということだ。
グーグルがクロールしやすいように手助けすることで、その後のSEO活動の舞台を整え仕事を円滑に進められる。
生ログ解析はテクニカルSEOの1つの側面であり、ログで見つかる問題を修正すれば、検索順位を引き上げてトラフィックを増やし、コンバージョンや売り上げを伸ばす助けになる。
生ログ解析を行う理由のいくつか(ほんの一部だが)を示しておこう。
サイトがエラーをあまりに多く返していると、Webサイトのクロール頻度をグーグルが減らす可能性があり、さらには順位の低下につながりかねない。
検索エンジンに新旧すべてのページをクロールさせて、(何よりも)検索結果ページに表示される順位を獲得したい。
すべてのURLリダイレクトで、受け取った「リンクジュース」を確実に次に渡すことが肝要だ。
しかしながら、残念なことに、生ログ解析はSEOのコミュニティでほとんど話題にならない。
だからここで、生ログ解析に役立ててほしい入門ガイドをMozコミュニティのみんなに提供したい。何か質問があったら、遠慮せずにコメント欄に書き込んでほしい!
生ログファイルとは
コンピュータサーバーや、オペレーティングシステム、ネットワーク機器、コンピュータアプリケーションは、何らかのアクションを実行すると常にログエントリ(記録)と呼ばれるものを自動で生成し、どこかに保存する。何が起きたのかをあとから管理者が確認できるようにするためだ。
SEOやデジタルマーケティングにおいては、ボットや人間が訪れてページのデータを取得しようとすることも、サーバーから見ればアクションの1つだ。
サーバーのログエントリは、ワールドワイドウェブコンソーシアム(W3C)の共通ログファイル形式で出力されるようプログラムされている。
では、ログエントリにはどんな情報が含まれているのだろうか。以下に、ウィキペディアで挙げられている例に僕の説明を添えて解説する。
たとえば、次のようなログエントリがあったとする。
127.0.0.1 user-identifier frank [10/Oct/2000:13:55:36 -0700] "GET /apache_pb.gif HTTP/1.0" 200 2326ここには、次のような情報が含まれている。
127.0.0.1 ―― リモートホスト名。この例のように、DNSホスト名が不明な場合やDNSLookupが無効の場合は、常にIPアドレスが表示される。
user-identifier ―― リモートログ名またはユーザーのRFC 1413によるアイデンティティ(あまり重要ではない)。
frank ―― ページをリクエストしている人物のユーザーID。僕の場合は、Mozにログインした後にページを訪れると、Mozのプロフィールに記載されている情報に基づき、ログエントリには「SamuelScott」または「392388」と表示される。
[10/Oct/2000:13:55:36 -0700] ―― 当該アクションの日付、時間、タイムゾーンがstrftime形式で表示される。
GET /apache_pb.gif HTTP/1.0 ―― 「GET」は、HTTPリクエストで実行できるいくつかのコマンドのうちの1つだ(ほかに「POST」「HEAD」などいくつかある)。「GET」はURLを取得するコマンドで、「POST」は(フォーラムのコメントといった)何らかのデータを送信するコマンドだ。スペースで区切って続く項目は、アクセスされるURLと、そのアクセスで利用しているHTTPのバージョンを表している。
200 ―― 返されたドキュメントのステータスコード。200なら成功だし、404なら見つからなかったことを表すといった具合だ。
2326 ―― 返されたドキュメントのサイズ(単位はバイト)。
Webサイトを動かしているサーバーに、ユーザー(またはGooglebot)がアクセスするたびに、サーバーは、これらの情報を記載した行を出力して記録し、ファイルなどの形で保存している。
ログエントリは絶え間なく生成されており、そのサーバーやネットワーク、アプリケーションがどれくらい頻繁に使用されているかによって異なるが、1秒間に数件~数千件が作成される。
ログエントリの集まりはログファイル(通常の会話では単に「ログ」)と呼ばれ、直近のログエントリが最下部に表示される。通常、1つのログファイルには、0時から24時までの1日分のログエントリが含まれる。
ログファイルにアクセスする
ログファイルの保存や管理の仕方は、サーバーの種類によって異なる。次に挙げるリンクは、最も普及している3種類のサーバー上で、ログデータを確認して管理するための総合的なガイドだ。
- Apacheのログファイルにアクセスする(Linux)
- NGINXのログファイルにアクセスする(Linux)
- IISのログファイルにアクセスする(Windows)
ログ解析とは
ログ解析(またはログアナリティクス)とは、生ログファイルを調べて、データから何らかを学びとるプロセスだ。ログ解析を行う一般的な理由には、以下が挙げられる。
開発と品質保証(QA) ―― プログラムやアプリケーションを開発して、適切に機能させるため、問題のあるバグがないかチェックする。
ネットワークのトラブルシューティング ―― ネットワークのシステムエラーに対応し、これを修復する。
顧客サービス ―― 技術的な製品で顧客が問題に遭遇した時に、何が起こったかを判断する。
セキュリティの問題 ―― ハッキングなどの侵入インシデントを調査する。
コンプライアンスの問題 ―― 企業のポリシーや政府の政策に応えて、情報を収集する。
テクニカルSEO ―― 僕のお気に入りはこれだ! 後で詳しく説明しよう。
ログ解析が定期的に行われることはほとんどない。通常、ログファイルを調べるのは、バグやハッキング、召喚令、エラー、誤動作などを受けて行う場合に限られる。継続的にやりたくなるようなものではないのだ。
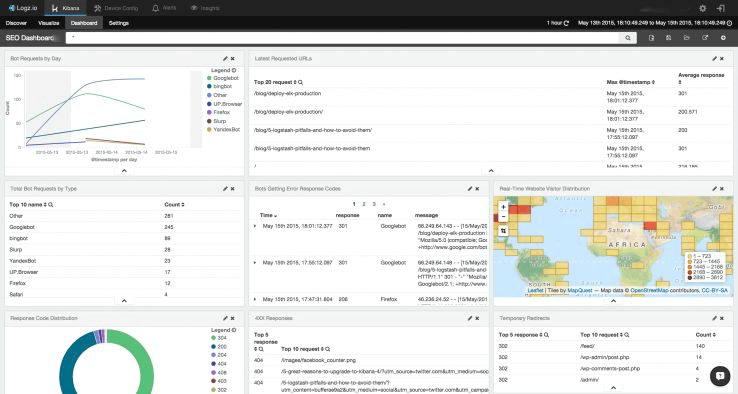
なぜかって? 以下に示すのは、わが社のサーバーが出力したままの(構造化されていない)ログファイルのほんの一部を写したスクリーンショットだ。
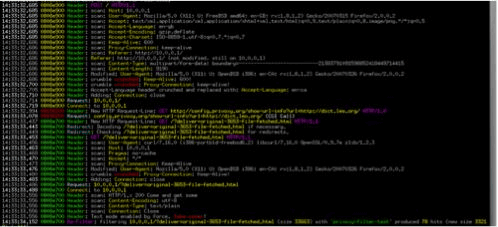
とんでもない量だ。Webサイトに1万人の訪問者があって、それぞれが1日あたり10ページにアクセスするとしたら、サーバーが作成するログファイルには、毎日10万件のログエントリが含まれることになる。実際にはこれ以外にも画像ファイルへのアクセスもすべてログエントリとして記録されているとしたら、すべてを手作業で調べる時間など、誰にもない。
この記事は、前後編の2回に分けてお届けする。後編となる次回「解析編」は、生ログ解析を楽にするツールと、ログ解析で何を調べればいいのかについて紹介する。→後編を読む




この記事は、Moz Blog に掲載された以下の記事を日本語訳したものです。

原文:「How to Use Server Log Analysis for Technical SEO」 by Samuel Scott (2015/05/26)
必見! Facebookいいね! 人気記事
最近(過去90日間)の記事で、Facebookの「いいね!」が多かった記事をお見逃し無く。

ソーシャルもやってます!