テクニカルSEOに効く! Webサーバーの生ログ解析は知っておいて損はない(解析編)
テクニカルSEOのための、Webサーバーの生ログ解析の基本を解説するこの記事は、前後編の2回に分けてお届けしている。
今回は、生ログ解析を楽にする「Splunk」や「ELK Stack」といったツールの情報と、生ログ解析で何を調べるべきかについて見ていこう。
「クロールボリューム」「クロールバジェット」「リダイレクト」「エラー」「重複URL」などなど、具体的な項目を紹介する。→まず前編を読んでおく
生ログ解析の方法
一般に、SEOなどでの生ログ解析を簡単にするには、次の3つの方法がある。
- Excelでがんばる
- SplunkやSumo Logicなどの商用ソフトウェアを使う
- オープンソースソフトウェアのELK Stackを使う
少し前になるが、ティム・レズニック氏によるMozの記事で、ログファイルをExcelにエクスポートする手順を紹介していた。これは、シンプルなログ解析を(比較的)手早く簡単に行える方法だが、欠点は、断片的なデータを確認できるにすぎず、全体のトレンドは把握できないことだ。最適なデータを入手するには、商用ツールかELK Stackを使う必要がある。
SplunkとSumo Logicは商用のログ解析ツールで、主に大企業で使われている。ELK Stackは、3つのプラットフォーム(Elasticsearch、Logstash、Kibana)からなる無料のオープンソースバッチで、Elasticが所有しており、小規模な企業で使われることが多い(実は僕たちも、社内システムの監視や、自社開発したログ管理ソフトウェアの基盤にELK Stackを利用している)。
テクニカルSEOの解析や、システムまたはアプリケーション性能の監視などにここで紹介する手順を利用してみたい人は、当社CEOのトメル・レヴィがELK Stackの導入ガイドを書いているので、参考にしてほしい。
ログデータで何を調べるのか
ログデータにどのようにアクセスして理解するとしても、テクニカルSEOにおいては、必要に応じて対処すべき重要な問題がたくさんある。ここでは、当社のテクニカルSEOダッシュボードのスクリーンショットとWebサイトのデータを示して、ログで何を調べるべきかを説明しよう。
ボットのクロールボリューム

重要なのは、Googlebotや、Baiduspider(百度)、Bingbot、YandexBotなどから一定期間に送られるリクエストの数を把握することだ。
たとえば、ロシアの検索で見つけてほしいのにサイトがYandexにクロールされていないとしたら、それは問題だ(Yandex.Webmasterの情報を調べるか、Search Engine Journalの記事を確認してみよう)。
レスポンスコードのエラー

Mozには、さまざまなステータスコードの意味に関する格好の入門記事がある。僕は、4XXと5XXのエラーがあればすぐわかるように、アラートシステムを設定している。これらのエラーはきわめて重要だからだ。
一時的リダイレクト

一時的にURLを転送する302リダイレクトは、外部リンクの「リンクジュース」を旧URLから新URLに渡さない。ほぼ例外なく、恒久的転送の301リダイレクトに変更するほうがいい。
クロールバジェットの無駄遣い

グーグルは、多くの要因に基づいて各Webサイトにクロールバジェットを割り当てている。
「クロールバジェット(クロール予算)」とは、そのサイトをたとえば1日に何ページ分クロールするかの割り振りだ。検索エンジンのロボットはインターネット上のあらゆるサイトをクロールしようとするが、ロボットの数は無限ではない。そのため、どんなサイトでもどの程度クロールしてもらえるかは有限なのだ。
たとえば、あなたに割り当てられているクロールバジェットが1日あたり100ページ(あるいはそれに相当するデータ量)だとしたら、そのすべてが確実にSERPに表示されるようにしたいと思うだろう。robots.txtファイルやmeta robotsタグにどう記述していようと、クロールバジェットが広告のランディングページや内部スクリプトなどで無駄に消費されている可能性はある。これを教えてくれるのがログだ。
上記のスクリーンショットでは、スクリプトが生成する、クロールさせる意味が薄いURLへのアクセスの例を赤で囲んで示している。
クロールの限界に達してしまえば、インデックス化して検索結果に表示してもらいたい新規コンテンツがあっても、グーグルに見つけてもらえないまま放置されるかもしれない。
重複するURLへのクロール
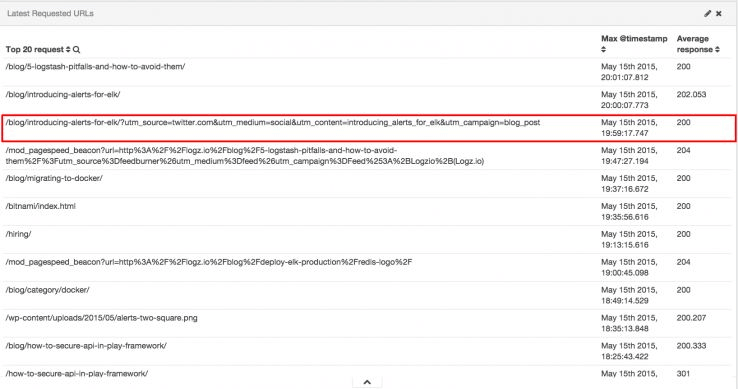
マーケティング目的で「ユーザーがどの広告からサイトを訪問したのか」をトラッキングするために、URLパラメータを使うことがある。
しかし、こうしたトラッキングパラメータを追加すると、検索エンジンは同じコンテンツを異なるURLのページとしてクロールするため、クロールバジェットが無駄に費される結果になることが多い。
この問題に対処するには、次のようなリソースが参考になる。
- グーグルのフォーラムページ
- グーグルのヘルプ「重複するURLの影響について」
- グーグルのヘルプ「URLパラメータページでパラメータを分類する」
- Search Engine Landの記事
クロールの優先順位

Webサイトの重要なページやセクションがグーグルに無視されている(クロールもインデックス化もされていない)かもしれない。ログを見れば、どのURLやディレクトリが最も注目されているか、あるいは最も注目されていないかが、わかる。
たとえば、電子書籍を公開し、ターゲットにしている検索クエリで検索順位を上げたいと狙っていても、グーグルが半年に1回しか訪れないディレクトリに置いていれば、最悪の場合半年間、その電子書籍でオーガニック検索のトラフィックは得られないということになるかもしれない。
Webサイトの中に、更新も十分行っているのにクロール頻度が不当に低いと思われるところがあるなら、内部リンク構造をチェックして、XMLサイトマップでクロールの優先順位の設定を確認した方がいいかもしれない。
最終クロール日
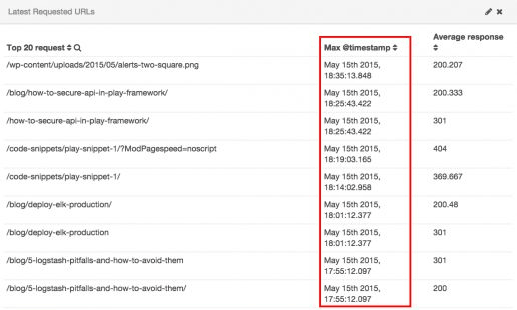
アップロードしたコンテンツは早くインデックス化してほしいものだ。ログファイルを見ると、グーグルのクロールした日付がわかる。
クロールバジェット
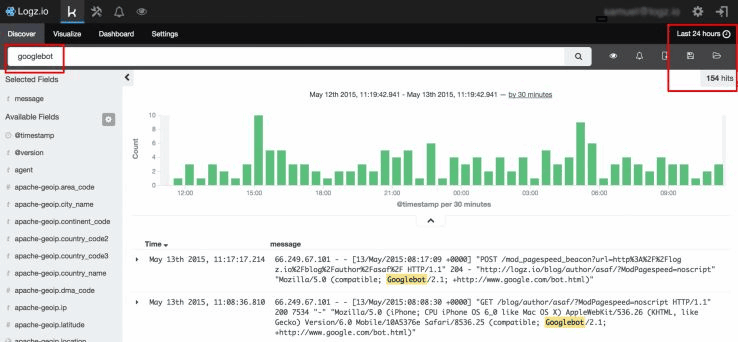
個人的な興味だが、サイト上でのGooglebotの動きをリアルタイムで確かめてみたい。
検索エンジンがWebサイトに割り当てるクロールバジェットは、グーグルがそのサイトをどの程度「気に入っている」かを、漠然としか、それもきわめて漠然としか教えてくれないからだ。
グーグルの理想を言うなら、貴重なクローリング時間を出来の悪いWebサイトに浪費などしたくないのだ。
ちなみに、Googlebotは、新興企業である当社の新しいWebサイトに対して、直近の24時間に154件のリクエストを出した。この数字が増えることを願っている!
テクニカルSEOにおいてログ解析がいかに重要か、理解してもらえたことと思う。さて、夜の11時だ――あなたは今、自分の生ログがどこにあるかわかっているだろうか?
参考資料
- Log File Analysis: The Most-Powerful Tool in Your SEO Toolkit(ログファイル解析:SEOツールキットの最強ツール)(トム・ベネット氏がBrightonSEOカンファレンスで使用したスライド)
- SEO Finds in Your Server Log(サーバーログから始めるSEO)、パート2:Googlebotに最適化(ティム・レズニック氏によるMozの記事)
- Googlebot Crawl Issue Identification Through Server Logs(サーバーログを通じたGooglebotクロール問題の認識)(デビッド・ソッティマーノ氏によるMozの記事)
- 詳細情報:ELK StackのLogstashおよびKibana(Logz.io)





この記事は、Moz Blog に掲載された以下の記事を日本語訳したものです。

原文:「How to Use Server Log Analysis for Technical SEO」 by Samuel Scott (2015/05/26)
必見! Facebookいいね! 人気記事
最近(過去90日間)の記事で、Facebookの「いいね!」が多かった記事をお見逃し無く。

ソーシャルもやってます!