JSフレームワーク時代に必要なGooglebot分析とスクレイピングの技術(テクニカルSEOの復権全6回の3)
「SEOにテクニカルな要素はもうない」というのは本当だろうか? 今の時代に改めて重要性が増しているテクニカルSEOを解説するこの記事、全6回の3回目は、「クロール」と「スクレイピング」について考えてみよう。
まず前回までを読んでおく
→第1回「ウェブ技術の進化」「JavaScript」「HTTP/2」
→第2回「SEOツール」「検索順位」「クローキング」
クロールに関するテクニカルな面の再考
SEO担当者が調べる必要のある基本的要素としてのコンテンツアクセシビリティは、昔と比べてさほど変化していない。変化しているのは、調査のために必要な解析作業の種類だ。
すでに知られているように、グーグルのクロール機能は大きく向上しており、エリック・ウー氏のような人たちは、JSCrawlability.comなどの実験でこうした機能の詳細を明らかにする優れた取り組みを行っている。
筆者も同じように、ページが読み込まれたときにGooglebotがどのような動作をするのかを確認する実験をしたいと考えた。そこで、ページを取得するときのGooglebotの様子を動画で記録しようと試みた。使ったのはLuckyOrangeだ。

筆者はまだインデックス化されていないページにLuckyOrangeスクリプトを実装して設定し、ユーザーエージェントに「googlebot」が含まれる場合のみ起動されるようにした。そして、準備が整ったところで、Search Consoleから「取得してレンダリング」を実行した。
マウスが動いてフォームへの入力が行われるものと期待していた。だが、カーソルが動くことはなく、数秒間Googlebotがそのページにアクセスしただけだった。
その後、GooglebotからそのURLにもう一度アクセスがあったことを確認した。それからほどなくして、そのページがインデックスに表示されたのだ。ただし、その2回目のアクセスはLuckyOrangeに記録されなかった。
筆者はもっと大規模なサイトで広範囲にテストを行い、先の結果を確認したいと考えている。前回の実験結果から考えると、Googlebotがそのサイトにアクセスし、ヘッドレスクローラーでクロールする必要があるページまたはサイトであるかどうかを判断することが予測される。Googlebotはその判断に基づいて、適切なクローラーを使用してそのサイトに戻ってくるのだろう。
筆者はみなさんもこのテストを行うことをお勧めする。たとえば、LuckyOrangeならば次のようなコードを使えばいい(LuckyOrangeを使用しなければいけないというわけではなく、HotJarなどでもいい)。
jQuery(function() {
Window.__lo_site_id = XXXX;
if (navigator.userAgent.toLowerCase().indexOf('googlebot') > -1)
{
var wa = document.createElement('script');
wa.type = 'text/javascript';
wa.async = true;
wa.src = ('https' == document.location.protocol ? https://ssl' : 'http://cdn') + '.luckyorange.com/w.js';
var s = document.getElementByTagName('script')[0];
s.parentNode.insertBefore(wa,s);
// Tag it with Googlebot
window._loq = window._low || [];
window._loq .push(["tag", "Googlebot"]);
}
});
この話で何を伝えたいかというと、次のようなことだ。
クロールにおいてグーグルが何を確認するか、またその確認を何回行うかといったことは、今もわれわれがSEO担当者として答える必要のある重要な質問だ。
イマドキのクロールのログファイル分析
ログファイルの分析は楽しい仕事ではないが、特に大規模なサイトのSEOプロジェクトでは、絶対に必要な作業だと言える。サイトが複雑化しているため、今はその必要性がかつてないほど高まっていると思われる。
マーシャル・シモンズ氏の話をすべて聞いてみよう。特にログファイル分析に関する話はお勧めだ。
このような目的で分析を行う場合には、グーグルのSearch Consoleのクロール統計はまったく役に立たない。

では、実際のところ、この「クロール統計」は何を示すものなのだろうか。ありがたいことに、この統計を見れば、グーグルが2月のある時期に大量のページをクロールしたことがわかる。実にクールな話だ。
ログファイル分析ツールは、ELKスタック(ElasticSearch、Logstash、Kibana)に含まれるKibanaやLogz.ioなど多くの製品が出回っている。だが、Screaming FrogがLog File Analyzerの最新製品をリリースし、この分野で急成長を見せている。
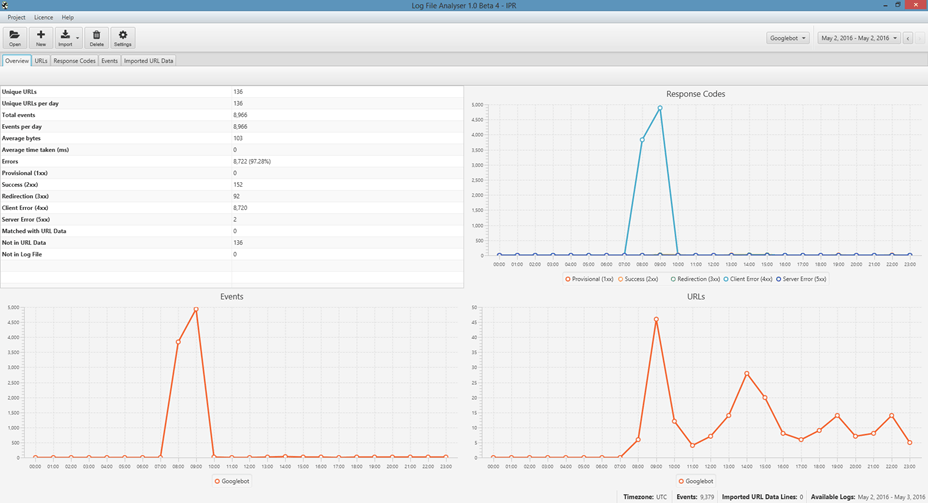
このツールで注目すべきは、数百万件のレコードを簡単に処理できる能力がある点だ。このことから、同じくScreaming Frogが開発しているSEO Spider Toolも同程度の能力を持つようになるのではと筆者は期待している。どの企業のツールであれ、ツールがもたらす情報は、実際に起こっていることを知るうえで非常に貴重だ。
2015年のことだが、あるクライアントがわれわれに対して、次のように強く主張したことがあった。
オーガニック検索からのアクセスを失ったのは、ペンギンアップデートのせいではない。
その原因は、検索数に貢献していたと思われる他の従来型のキャンペーンやデジタルキャンペーンが終了したことか、あるいは季節的要因か何かだ。
そこで筆者はログファイルを取り出し、彼らのキャンペーンが行われていたときからのデータをすべて調べてみた。すると、彼らが考えていたようなことは1つも起こっていなかった。
実際には、Googlebotの活動がペンギンアップデート以降に急激に減少し、それと同時にオーガニック検索のトラフィックが減少していたのだ。ログファイルはそのことを明確に示していた。

上記の例では、Googlebotはページの質の高さや張られたリンクの多さに基づいてクロールしているという従来の常識が通用した。
だが、われわれが最近のクライアントについて「ソーシャルシェア」「リンク」「Googlebotのアクセス数」を重ねて比較したところ、リンクよりもソーシャルシェアのほうがクロールとの相関が強いことがわかった。
以下のデータを見ると、リンクが最も多いサイトのクロールの数が最も少ない。
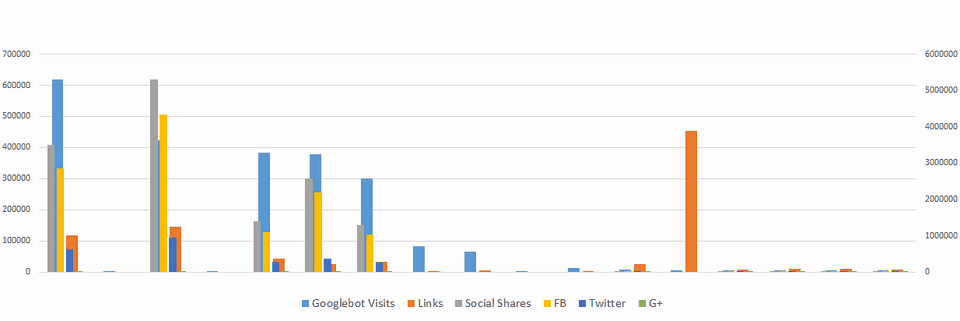
このようなことは、時間をかけてログファイルを詳しく調べなくても推測できる重要な情報だ。
AngularJSを理解するためにログファイルを活用する
JavaScriptのアプリケーションフレームワークであるAngularJSを使っているサイトでも、すべてのリクエストの結果がログに記録される。他のウェブページやアプリケーションと同じだ。
だが、サーバーの設定によっては、AngularJSの設定に関して取得できる情報が数多く含まれていることがある。何らかのスナップショットテクノロジを使用してプリレンダリングを行っている場合は特にそうだ。
われわれは、あるクライアントで、スナップショットシステムがキャッシュを更新する必要があるときに、時間がかかりすぎてタイムアウトになる場合が多いことを発見した。Googlebotは、このような状況を5XXエラーと判断する。
そのため、これらのページはインデックスから除外され、時間が経つにつれて順位が激しく変動したり、サイトの他のページに取って代わられたりするようになるのだ。

さらに、Googlebotが人間のユーザーと勘違いされていた例も多く見つかった。この場合、Googlebotには、HTMLスナップショットではなく、AngularJSで生成されるページが表示されていた。
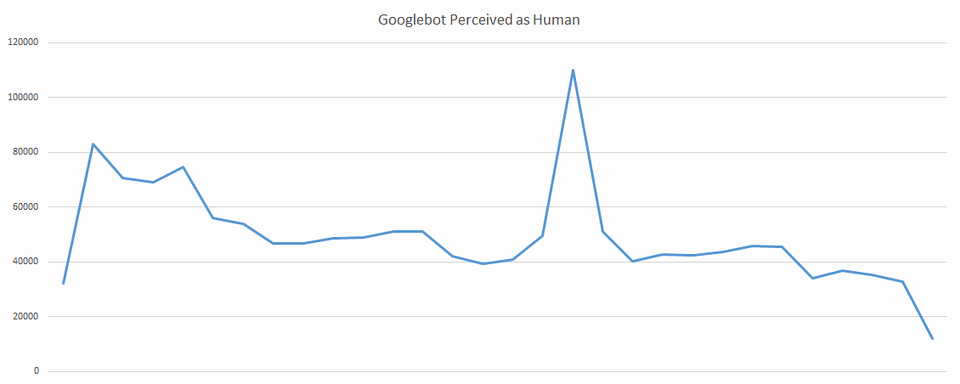
だが、GooglebotがこれらのページのHTMLスナップショットを確認できないにもかかわらず、これらのページはインデックスに格納され、適切な検索順位を獲得していた。そのため、われわれはクライアントと共同でテストを行い、サイトのスナップショットシステムを削除したところ、オーガニック検索のトラフィックが向上する結果となった。
これは、グーグルがAJAXクロールスキームの廃止を発表する際に述べていたことと、まさしく一致している。グーグルは、JavaScriptでレンダリングされているコンテンツにアクセスし、読み込まれたときに表示される内容をすべてインデックス化できる。

だからといって、HTMLスナップショットシステムを使用する価値がないわけではない。プリレンダリングされたページに対しては、Googlebotがよりすばやく頻繁にクロールを行う傾向がある。筆者はその理由を、グーグルがコンピュータにそれほど負荷をかけずにこのようなクロールを実行できるからではないかと推測している。
結局のところ、HTMLスナップショットは今もベストプラクティスだと言えるだろう。ただし、グーグルがこのようなサイトを確認する方法が他にもあることは間違いない。
グーグルはHTMLスナップショットについて、グーグルのためにのみ提供するのではなく、ユーザーへの表示速度を上げるために提供すべきだと述べている。
通常、Google のためだけにプリレンダリングする必要はありません。プログレッシブ エンハンスメントの原則に沿いつつ、パフォーマンス最適化のためプリレンダリングを行う場合、プリレンダリングしたコンテンツと、通常のユーザーに対して表示するコンテンツが、見た目上も体験上も同じになるようにしてください。
Googlebot に対して提示するコンテンツと、通常のユーザーに対して表示するコンテンツが異なる場合はクローキングと見なされ、ウェブマスター ガイドライン違反と判断されることがあります。
この判断は高度にテクニカルであり、オーガニック検索のビジビリティに直接影響を与える。
この1年間にわれわれiPullRankのチームに加わったSEO担当者と話をした経験から言えば、このようなコンセプトを理解している人や、HTMLスナップショットの問題を診断できる人は、ほとんどいない。しかし、今やこれらの問題はよく見かけるものであり、こうしたテクノロジの採用が進むにつれて深刻化していくだろう。まさにテクニカルなSEOだ。
ただし、スナップショットをユーザーに対しても提供する場合、次のような疑問が生じる。「そもそもこのフレームワークを利用することにした理由は何だったのか」という疑問だ。
当然ながら、テクノロジ分野の判断はSEOの範囲を超えるものだ。だが、MeteorJSのように、アプライアンスを必要としないフレームワークの利用を検討してもよい。

そうではなく、あくまでもAngularを使用したいと考えている場合は、新しいAngular UniversalをサポートするAngular 2を検討してみよう。Angular Universalは、いわゆる「isomorphic」なJavaScriptで、これを使えばサーバーサイドでコンテンツをプリレンダリングすることもできる。

Angular 2はAngular 1.xと比べて多くの機能が改善されているが、それについてはグーグルの言葉を借りて説明しよう。
奇妙なフレームワークがあれこれ登場する前から、グーグルは新しいテクノロジに対して1つの考え方を取っている。それが「プログレッシブエンハンスメント」だ。多くの新しいIoTデバイスが登場しつつあるなかでは、ウェブサイトが提供するコンテンツを、最も機能が少ないデバイスに合わせて構築し、そのようなデバイスがサイトを表示できるように、余分な機能は無効にするべきだ。
サイトを一から作成する場合は、HTML のみを使用してサイトの構造とナビゲーションを構築することをおすすめします。その後、サイトのページ、リンク、コンテンツを配置し、AJAX を使用して外観やインターフェースをデザインします。
これにより、Googlebot は HTML を参照でき、ユーザーは最新のブラウザを使用して AJAX の機能を活用できます。
これはつまり、自分のコンテンツに誰もがアクセスできるようにするということだ。筆者にこのことを思い出させてくれたフィリ・ワイゼ氏に感謝したい。
SEO解析におけるスクレイピングの致命的な欠陥
スクレイピング(ページのHTMLをWebサーバーから取得すること)は、SEOツールが行うあらゆる動作に欠かせない。
cURL
cURLは、HTTPリクエストを作成および処理するためのライブラリだ。よく使われるほとんどのプログラミング言語には、ライブラリを使用するためのバインディングがある。そして、ほとんどのSEOツールが、そのライブラリや類似のものを利用してウェブページをダウンロードする。

cURLは、FTPから単一のファイルをダウンロードするときと同じように動作する。だが、ウェブページに関して言えば、ページ全体を表示することはできない。HTMLが参照しているすべての画像やCSSなどのファイルを自動的にダウンロードするわけではないからだ。
このことが、ほとんどのSEOソフトウェアの致命的な欠陥となっている。これは、ソースの表示がもはやページのコードを表示するための有効な手段ではないのとまったく同じ理由だ。ページが読み込まれるときにJavaScriptやCSSによる変換処理が何度も行われ、グーグルはヘッドレスブラウザを使ってクロールを行うため、グーグルが目にする実際の内容を知るには、コード(の要素)を検証する必要がある。
ここで、ヘッドレスブラウザが関与することになる。
PhantomJS
ヘッドレスブラウザのライブラリとしてよく知られているものの1つに、PhantomJSがある。

SEO分野以外のツールの多くは、このライブラリを使用して作成され、ブラウジングを自動化している。たとえばNetflixは、ページのスクレイピングとスクリーンショット取得を行うSketchyと呼ばれるツールを開発してさえいる。
PhantomJSは、QtWebkitと呼ばれるレンダリングエンジンから作成されているが、これはSafari(およびグーグルがBlinkをフォークする前のChrome)のベースとなっているコードと同じものからフォークしたものだ。PhantomJSには最新のブラウザのような機能はないが、SEO解析に必要なほとんどの作業に対応できるだけの機能が備わっている。
GitHubのリポジトリを見ればわかるように、Prerender.ioなどのHTMLスナップショットソフトウェアも、このライブラリを使用して作成されている。
PhantomJSには一連のラッパーライブラリがあり、さまざまな言語で簡単に使用できるようになっている。これをNode.jsで使用することに関心がある読者は、HorsemanJSをチェックしてほしい。

PHPの方がなじみがあるという読者は、PHP PhantomJSをチェックしよう。

Headless Chromium
ヘッドレスブラウザの世界に最近登場した高品質のツールに、Headless Chromiumがある。名前から想像できるように、これはChromeブラウザのヘッドレス版で、Googlebotの簡易版のようなものだと言ってもいいくらいだ。

したがって、SEO事業者が今後自社のクロールインフラを見直すのならば、おそらくHeadless Chromiumがもっとも検討すべきツールとなるだろう。たとえ上級ユーザーのみが対象だったとしてもだ。
Headless Chromeについて詳しく知りたい読者は、サミ・キョスティラ氏とアレックス・クラーク氏のBlinkOn 6での発言をチェックしてほしい。
ツールでは実行できないことをブラウザによるスクレイピングで実行
多くのSEOツールは完全にレンダリングされたDOMを調べることができないが、SEO担当者はその状況を受け入れるしかないわけではない。ヘッドレスブラウザを利用しなくても、ちょっとしたJavaScriptを作成するだけで、Chromeをスクレイピングマシン化できるのだ。
筆者は「ウェブのすべてのページをスクレイピングする方法」という記事で、この件について詳しく取り上げている。ちょっとしたjQueryを使用すれば、ページの内容を選択してJavaScriptコンソールに出力し、好きな形でファイルにエクスポートすることが簡単にできるのだ。
このようなスクレイピングを行えば、サーバーサイドで行わなければならない認証管理やCookie管理と同じように、サイトに自分を本物のユーザーだと信じてもらうために必要だった大量のコードが不要になる。
もちろん、このようなスクレイピングは、ソフトウェアを開発する場合ではなく、単発の作業を行う場合に適している。
ArtooJSというブックマークレットは、ブラウザでスクレイピングしたり一連のページを自動的にスクレイピングしたりして、その結果をJSON形式のファイルに保存してくれる。

こういった処理を行うためのさらに高度な機能を備えているのが、WebScraper.ioと呼ばれるChromeの拡張機能だ。これを使うのにコードは必要なく、すべての処理をマウスを何度かクリックするだけで実行できる。

この記事は、6回に分けてお届けしている。4回目となる次回は、テクニカルSEOの立場から「コンテンツ」と「リンク」について考えてみる。 →第4回を読む



この記事は、Moz Blog に掲載された以下の記事を日本語訳したものです。

原文:「The Technical SEO Renaissance: The Whys and Hows of SEO's Forgotten Role in the Mechanics of the Web」 by iPullRank (2016/10/25)
必見! Facebookいいね! 人気記事
最近(過去90日間)の記事で、Facebookの「いいね!」が多かった記事をお見逃し無く。

ソーシャルもやってます!