301リダイレクトとrel="canonical"の違いとどちらを使うべきか?
海外のSEO/SEM情報を日本語でピックアップ
301リダイレクトとrel="canonical"の違いとどちらを使うべきか?
基本は汎用的な301リダイレクト (Google Webmaster Central Help Channel on YouTube)
rel="canonical"を説明した2009年のビデオでは、301リダイレクトが使えないときにrel="canonical"を使うようにアドバイスしていました。
でも301リダイレクトを使うと、(転送のため)ブラウザに余分なステップが入ることから、サーバーのパフォーマンスを落とすことになります。
ということは、301ではなくてrel="canonical"を使うべきだということなのでしょうか?
ウェブマスターからよせられたこの質問に、グーグルのマット・カッツ氏が回答した。
サーバーの完全な管理権限があるならどちらでもかまわない。
ただ、ほとんど場合に301リダイレクトを推奨する。
ブラウザも検索エンジンもすべてが301リダイレクトをどう処理すべきかわかっているからだ。しかしベンチャー企業の小さなサービスはrel="canonical"を適切に扱えないかもしれない。
たしかに301リダイレクトは余分なURLを介すが、通常は1つだけなのでたいした問題にはならない。
それに最初のURLがブラウザのアドレスバーに表示されてからリダイレクトされそういうふうなものだとユーザーに認識されていてわかりやすい。
条件が等しくて301リダイレクトとrel="canonical"のどちらも利用可能ならば、すべてのサービスが適切に処理できる点と認知度の点から301リダイレクトを勧めるよ。
とはいえ使い方をよく知っていてサーバーの管理権限がなかったりするのであればrel="canonical"を使ってももちろん構わない。
301リダイレクトは古くから使われ、インターネット(HTTPプロトコル)の仕様であるから幅広くサポートされている。
一方で、rel="canonical"タグはグーグルとヤフー、マイクロソフトが共同で策定した仕様であり、他の検索エンジンがサポートしていないこともあり得る。またグーグルとマイクロソフト(Bing)では取り扱い方に違いがある。
rel="canonical"は検索エンジン側では301リダイレクト相当の働きをするが、ブラウザやユーザーの認識まで含めると、まったく同じ仕組みだということではないのだ。
原則的に、301リダイレクトが使えるなら301リダイレクトを利用するのが好ましい。たとえば、wwwの有無やindex.htmlの有無を正規化する場合だ。
ところがサーバーの設定を変更する権限がなくて301リダイレクトが使えないのであれば、rel="canonical"を使ってこれらを正規化するしかない。
301リダイレクトを使うべきでないケースも存在する。たとえばトラッキング用のパラメータをURLに追加したりコンテンツの内容は同じだが並び替えによってURLのパラメータが変わったりする場合だ。このケースでは301を使うわけにはいかない。したがってrel="canonical"が適切な選択肢になる。
「SEOで勝つにはやっぱりコンテンツ」「著者情報が今後の鍵を握るか」「ローカル検索は外せない」SEO有用情報まとめ
海外カンファレンスからのお持ち帰り有用情報 (The Digital Marketing Blog by BlueGlass)
BlueGlassXというデジタルマーケティングのカンファレンスが12月3日~4日に米タンパで開催された。参加者による有用なツイートを95個、こちらの記事では紹介している。
そのなかから、SEOに関係していて特に役立ちそうなものを14個ピックアップする。
コンテンツがうまくいくかどうかに議論の余地はもはやない。グーグルは、それが進むべき唯一の道にしている。
SEO業界のいちばんの問題は、ほんの2週間先のような目先しか見ていない人々がいることだ。
リンク集めのための予算をコンテンツ重視の戦略に割り当てるようにクライアントに納得させなければならなかった。これは4月までは難しいことだった。
筆者注: クライアントもコンテンツがリンクよりも重要ということにやっと気付き始めたということだと思われる。
グーグルの自然検索は相当ローカル検索対応されてきていて、実店舗を営んでいない会社は厳しい。
特定の分野に強いライターを雇うこと。専門知識だけでなくその業界のネットワークももたらしてくれる。
著者情報は、コンテンツが誰の功績によるものなのかついての信頼を示すグーグルの最適な手段である。
グーグルの著者情報は匿名ライターを消滅させるだろう。
著者情報はグーグルが一歩前進したことの強い証拠だ。信頼あるエージェント(コンテンツ著者や著者のサイト)からのリンクを得なければならない。
ローカル検索で中心地のオリジナルコンテンツを作るには歴史の情報を利用するといい。
モバイル検索の結果は、都市の中心への距離とは対照的に検索者がいる位置に対して関連性がより強まってきている。
ローカル検索には強いサイテーションが必要。つまりビジネス名と住所、電話番号へのウェブ上での言及だ。
文のなかにリンクを置く。より自然だしクリック率が高くなる。
リンクは、ほかに正しくやってきたことの副産物でなければならない。
最初に聞かければならないことはクライアントのPPCのデータだ。何がうまく行っているか知り、そこから戦略を練る。
グーグルのマット・カッツに聞くローカルSEOの5つのTIPS
貴重なまとめ (LocalVisibilitySystem.com)
グーグルのマット・カッツ氏が過去にアドバイスしたローカル検索のTIPSをまとめた記事。
すべての都市を対象にはできない。たとえサービスを提供するエリアであったとしても、その場所に所在していなければローカル検索の結果には出てこない。残念だが仕方がない。
ウェブページにはビジネス名と所在地を必ず記載しておくこと。
FlashやJavaScriptのナビゲーションリンクやボタンは検索エンジンがクロールしづらいので避ける。
地域や支店ごとに専用のページを作る。以下の2点が大切。
- それぞれの支店のページには名前や住所、電話番号、営業時間など固有の情報を載せる。
- HTMLのサイトマップページから通常のリンクでそれらのページへリンクする。
地名だけを変えただけの形の同じページはよくない。地名だけを入れ替えた重複コンテンツになってしまう(各ページに独自のコンテンツを入れる必要がある)。
マット・カッツ氏がローカル検索について語ることはあまりないので、なかなか貴重なまとめだ。
グーグル翻訳を使ってGooglebotがアクセスできるかを検証
Fetch as Google代わりに使える裏ワザ (Google Webmaster Help Forum)
Googlebotがウェブページに正常にアクセスできるかどうかを調べるには、ウェブマスターツールのFetch as Googleが使える。しかし当然のことながら登録してある管理サイトでしか利用できない。
ところがグーグル翻訳を使うと、そのページにGooglebotがアクセス可能かどうかを知ることができる。
英語版のウェブマスター向けヘルプフォーラムでグーグル社員のジョン・ミューラー氏が教えてくれた裏技だ。
Fetch as Googleとは違い、返ってくるHTTPのヘッダー情報を見ることはできないが、GooglebotのIPアドレスからのリクエストになるのでユーザーエージェント(UA)のみならずIPアドレスで制限している場合でもアクセスの可否をチェック可能なのが特徴だ。
あるサイトがクローキングしているのではないかと疑われるが検索エンジンのキャッシュは無効にしている場合に、この仕組みを使ってチェックできる。知っておいて損はないだろう。
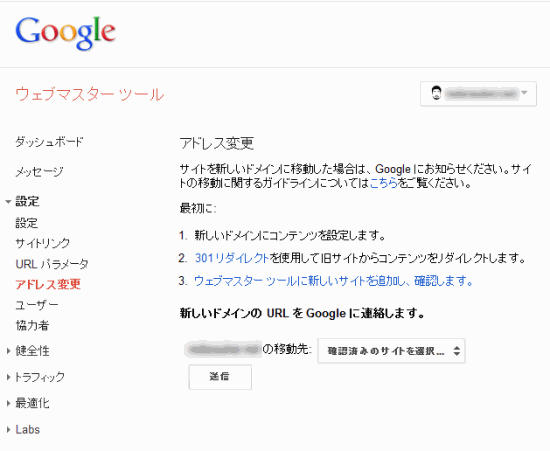
サイト移転時は移転元と移転先の両方をウェブマスターツールに登録するのか
必須ではないがしたほうがいい (Google Webmaster Help Forum)
301リダイレクトでサイトを移転するときは、グーグルウェブマスターツールに移転元と移転先の両方のサイトを登録すべきなのだろうか?
「必須ではないけれども、両方を登録するほうがいい」とグーグルのジョン・ミューラー氏はアドバイスしている。
理由は両方のサイトの状況を確認できるからだ。
たとえばインデックスステータスを見れば移転が正常に処理されているかがわかる。旧サイトのインデックス数は減少してくはずだ。反対に新サイトのインデックス数は増加していかなければならない。
また移転処理を速めるための「サイトの移転」ツールは移転元と移転先の両方を登録していないと利用できない。

 SEO Japanの
SEO Japanの
掲載記事からピックアップ
アルゴリズムを分析するSEOを不安視する記事とEMDアップデートを詳細に分析した対照的な2つを今週はピックアップ。
- 次世代SEOの行く末 – アルゴリズム中心のアプローチは死ぬか?
アルゴリズム分析を追うな、ユーザーを追え - GoogleのEMDアップデートを徹底解剖
英語圏を対象にしたサイト向け


鈴木 謙一(すずき けんいち)
「海外SEO情報ブログ」の運営者。株式会社Faber Companyの執行役員(Search Advocate)。
海外SEO情報ブログは、SEOに特化した日本ではもっとも有名なSEO系ブログの1つ。米国発の最新のSEO情報を中心に、コンバージョン率アップやユーザーエクスペリエンス最適化のための施策も取り上げている。
正しいSEOをウェブ担当者に習得してもらうために、ブログでの情報発信に加えて所属先のFaber Companyでは、セミナー講師や講演スピーカーを主たる役割にしている。
必見! Facebookいいね! 人気記事
最近(過去90日間)の記事で、Facebookの「いいね!」が多かった記事をお見逃し無く。
デジタルマーケティングの即戦力を2日間で育てます! 第26期「企業Web担当者 初級講座」6/5・6/6【2025年6月度】
 5,407 いいね!
5,407 いいね!Web担 編集後記 2025年5月
441 いいね!はじめてのGoogle広告入門講座 P-MAXキャンペーンやAIを活用! 予算の無駄をなくす「入札戦略」を学ぶ
409 いいね!X、コクヨ、日経新聞、三井住友海上、三田製麺、パシフィコ横浜、NECなど登壇【5/29、30 渋谷リアル&オンライン開催】
391 いいね!<第1回>無料ツールで始める“一人でできる”「Webサイト改善講座」~GA4・Clarity・サーチコンソール徹底活用【7時間集中講義】
167 いいね!参加してよかったエンジニアサマーインターンシップ、初めて1位を獲得した有名企業は?【サポーターズ調べ】
113 いいね!WordPress 情報共有の場「KUSANAGIサミット 2025 WordPress編」@6月21日(土)オンライン開催
83 いいね!

ソーシャルもやってます!