【2016年版】グーグル上位表示ページとランキング要因調査
- 今週のピックアップ
- 日本語で読めるSEO/SEM情報
- 海外SEO情報ブログの掲載記事から
- 海外のSEO/SEM情報を日本語で
- SEO Japanからのピックアップはなし
海外のSEO/SEM情報を日本語でピックアップ
【2016年版】グーグル上位表示ページとランキング要因調査
相関関係と因果関係は違う点に注意して傾向をつかみたい (Searchmetrics)
SEOツールを提供するサーチメトリックス(Searchmetrics)社が、米グーグル(google.com)で上位表示しているウェブページとさまざまなランキング要因との相関関係を調査し、その結果を公開している。
サーチエンジンランド(Search Engine Land)が特に興味深いと思われる結果を抽出しているので紹介する。
コンテンツの関連性が最も高いページは、3位~6位に表示されている
PC向けページのコンテンツはモバイル向けページよりもだいたい3倍長い
上位20位のなかで、
titleタグに検索キーワードが含まれているのは53%だけ上位10位のサイトの滞在時間は3分10秒
検索結果1ページ目のウェブページの直帰率は平均46%
1位~3位の検索結果でのクリック率は平均36%
上位10位のページのほぼ半分がHTTPS
上位10位のページの86%のドメイン名は「.com」
上位表示しているモバイル向けページは、対応するPC向けページの3分の1のサイズ(データの大きさ)
モバイル向けページはPC向けページよりもだいたい2倍速く表示
トップ100のドメイン名のサイトはすべてモバイル対応済み、トップ100より下のモバイル対応は78%
olやulのリストタグを利用しているサイトが顕著に増加ソーシャルシグナルとの相関関係は昨年と変わらず
バックリンクと上位表示の相関関係は、現在は1つの要因に過ぎない。依然として高いが、年々減少傾向にある
さて、こうした調査を見るときに大切なことだが、相関関係と因果関係は異なることに注意してほしい。この調査は、あくまでも上位表示しているウェブページやサイトに見られる傾向に過ぎない。
何を言いたいのかというと、この調査を見て「HTTPSにすれば上位表示される」「.comドメイン名を使うほうが順位が上がる」と考えるのは、正しくないということだ。
たしかに、HTTPSはランキング要因になっているが、影響力は微々たるもので、上位表示に直結するものではない。むしろ上位表示しているサイトはユーザーのプライバシー保護も重視するなど細かい点にも気が回ってサイトに反映しているから上位に来ていると考えたほうが自然だろう。
とはいえ、相関関係からわかる傾向にも価値はある。
たとえば、「titleタグに検索キーワードが含まれているのは53%(上位20位)」というデータに注目してみよう。
数年前なら、titleタグにキーワードが含まれないページの上位表示はあり得なかった。titleタグに重要なキーワードを入れる施策は、(かつては)SEOの基本中の基本だった。
しかし今は、titleタグにキーワードが入っていなくても上位表示しているウェブページは当たり前のように見かける。titleタグにキーワードを含める必要がなくなったということではないが、今のグーグルはtitleタグのキーワードに頼らずとも、各コンテンツのクエリとの関連性を的確に判断できるようになったということが言われているし、それが事実だということが確認できる。
つまり、これまで無理矢理titleタグに狙ったキーワードを入れるようにしていたならば、それはすでに不毛になってきている可能性があるということだ。
- SEOがんばってる人用(ふつうの人は気にしなくていい)
- ホントにSEOを極めたい人だけ
ランキングチェックツールはグーグルの利用規約違反!?
SEOには必要なツールだけど使用に注意 (Gary Illyes on Twitter)
グーグルのゲイリー・イリェーシュ氏が、こんなツイートを投稿した。
友好的な注意喚起: 検索エンジンに対してクエリを自動的に送ることは、ほとんどの場合は利用規約に違反する。
Friendly reminder that sending automated queries to search engines are generally against their Terms of Service.
— Gary Illyes ᕕ( ᐛ )ᕗ (@methode) 2016年12月14日
イリェーシュ氏が言ったことは、ヘルプにも明記されている。
Google の利用規約では、どのような種類かに関わらず、自動化されたクエリを Google から明示的な許可を事前に得ずに Google のシステムに送信することは禁止されています。
リソースの浪費につながる自動化されたクエリの送信には、WebPosition Gold などのソフトウェアを使って自動化されたクエリを Google に送信し、さまざまなクエリによる Google 検索結果におけるウェブサイトやウェブページのランキングを調べようとする行為が含まれます。
ランキングを調べることに加えて、その他の自動化された手段で許可なく Google にアクセスすることも、Google のウェブマスター向けガイドライン(品質に関するガイドライン)および利用規約への違反にあたります。
自動化クエリを送信する代表格は順位チェックツールだろう。SEOになくてはならないツールだという人もいるだろうが、使い方によっては規約違反になりうることは認識しておきたい。
こうしたことを改めて表明するというのは、もしかして、グーグルが順位チェックツールへの対策を進めているのではないか、そんな風に疑ってしまうが、実際にはどうなのだろうか。
- 順位チェックツールに頼っている人
サイトマップに書くURLは、www有無・HTTPS有無どれ? もしかして全部?
正規URLだけを掲載する (Webmaster Central Help Forum)
英語版のヘルプフォーラムに次のような質問が投稿された。
うちのサイトは次の3パターンのURLでアクセスできます。
- http://www.example.com/
- https://www.example.com/
- http://example.com/
このすべてをサイトマップで送信したらどうなりますか? ランキングに悪い影響が出ますか?
グーグルのジョン・ミューラー氏はこのようにアドバイスした。
インデックスさせたいURLだけを送信すればいい。全バリエーションのURLを送信してはいけない。
基本的なこととして、サイトマップに掲載するURLをおさらいしておこう。
サイトマップにはインデックスさせるURL、言い換えれば検索結果に表示させるURLだけを含める。
httpsのURLでインデックスさせたいのであれば、httpsのURLだけをサイトマップに記載する。wwwありのURLでインデックスさせたいのであれば、wwwありのURLだけをサイトマップに記載する。
そのほか、パラメータが付いたURLも、余分なパラメータを付けたり順番を入れ替えたりせずに、1つのページに対しては1つのURLだけを割り当てる。
SEOの専門用語で言えば、サイトマップに記載するのは正規URLだけということだ。
正規URLではないURLをサイトマップに含めると、想定していないURLがインデックスされてしまうこともある。「rel="canonical"ではwwwありのURLを指定しているのに、サイトマップではwwwなしのURLを記載している」といった矛盾した状態にならないようにも気を付けてほしい(大きな問題にはならないが、無駄が発生してしまう)。
ただし、裏技とも呼べる例外がある。サイトの移転やHTTPSへの移行を少しでも速く処理させたいときだ。
移転前のURLを載せたサイトマップや移行前のHTTPのサイトマップを送信する。するとGooglebotは、変更前のURLをクロールしに来るので、リダイレクトをいち早く認識するというカラクリだ。
グーグル側でのURL変更が完全に認識されたことを確認できたら、以前のURLが載ったサイトマップは削除する。
もっとも、必ずやるべきことでもない。忘れてしまっても何も問題ない。
- すべてのWeb担当者 必見!
- 裏技は、SEOがんばってる人用(ふつうの人は気にしなくていい)
schema.org/Personで「homeLocation がありません」エラーが発生
無視して大丈夫 (Webmaster Central Help Forum)
schema.org/Person の構造化データをサイトに設定している場合、「homeLocation がありません」というエラーが、しばらく前からSearch Consoleでレポートに出ているようだ。
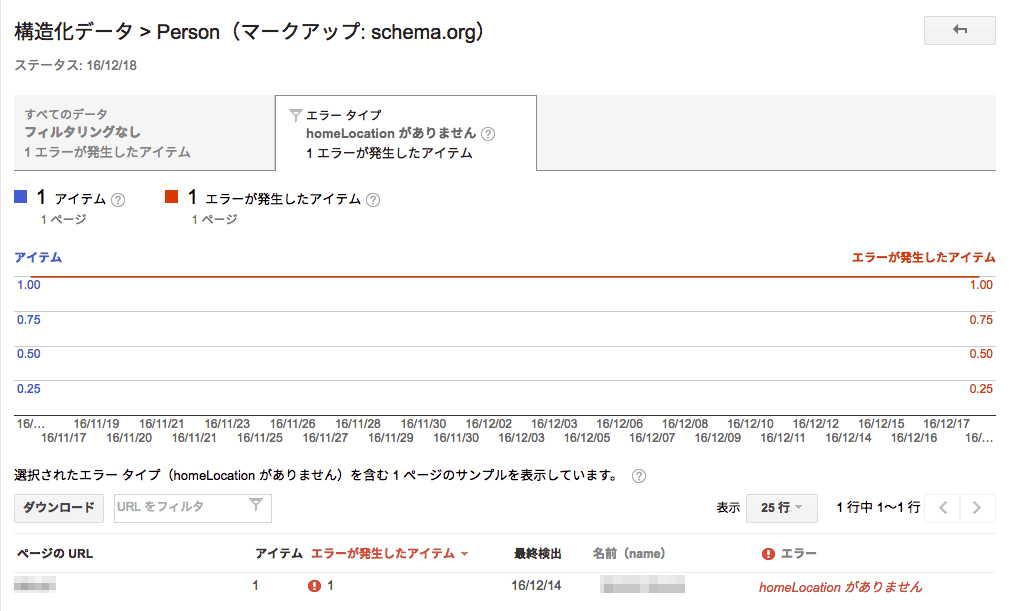
以前はこのhomeLocationプロパティがなくてもエラーは出ていなかった。グーグル側でなんらかの変更があったのだろう。
ジョン・ミューラー氏によれば、サイトのランキングに悪い影響を与えることないとのことで、無視してかまわないそうだ。もちろん追加してもかまわない。
- schema.org/Personを設定している人
- SEOがんばってる人用(ふつうの人は気にしなくていい)
noarchiveを指定しても、クロール・インデックス・ランキングには何も影響しない
キャッシュ表示しなくなるだけ (John Mueller on Twitter)
noarchive meta タグに関して、ジョン・ミューラー氏がツイッターでフォロワーに次のように説明していた。
noarchiveは、クロールやインデックス、ランキングを防ぐものではない。
@Way2Raman The "noarchive" doesn't prevent crawling, indexing, or ranking. https://t.co/WfP1f0MucX
— John ☆.o(≧▽≦)o.☆ (@JohnMu) 2016年12月19日
どうやら質問者は、noarchiveをクロール制御のために使われるmetaタグだと誤認識していたようだ。
noarchive は、キャッシュを公開しないようにするためのrobots metaタグだ。設置されたウェブページは検索結果ではキャシュリンクが表示されなくなるし、cache:コマンドを使って検索してもキャッシュを見ることができなくなる。
しかしグーグルは通常のウェブページとまったく同じようにクロール、インデックスする。評価にも何も影響しない。単純にキャッシュを非表示にするだけだ。
グーグルがサポートする主なrobots metaタグとその働きはヘルプページで説明されている。すべて把握しているかどうかを確認するために、目を通しておくといいだろう。
- 基本的なこととして一応みんなが知っておきたい

 SEO Japanの
SEO Japanの
掲載記事からピックアップ
更新停止中。再開はあるのか? それとも、この枠がどんどん薄くなっていって消えてしまうのか?



鈴木 謙一(すずき けんいち)
「海外SEO情報ブログ」の運営者。株式会社Faber Companyの執行役員(Search Advocate)。
海外SEO情報ブログは、SEOに特化した日本ではもっとも有名なSEO系ブログの1つ。米国発の最新のSEO情報を中心に、コンバージョン率アップやユーザーエクスペリエンス最適化のための施策も取り上げている。
正しいSEOをウェブ担当者に習得してもらうために、ブログでの情報発信に加えて所属先のFaber Companyでは、セミナー講師や講演スピーカーを主たる役割にしている。
必見! Facebookいいね! 人気記事
最近(過去90日間)の記事で、Facebookの「いいね!」が多かった記事をお見逃し無く。

ソーシャルもやってます!