IV 重複問題の解決に役立つ方法(続き)
IV 重複問題の解決に役立つ方法(続き)
IV-6 URLの削除(グーグル)
Googleウェブマスターツール(GWT)から、個々のページ(またはディレクトリ)をインデックスから手作業で削除するようリクエストを送信できる。[サイト設定]>[クローラのアクセス]を選ぶと3つのタブが並んでいるので、3つ目の[URLの削除]タブをクリックすると次のようになる。
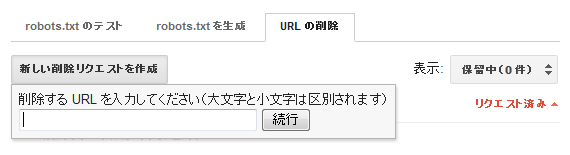

このツールはふつう、重複コンテンツの対処策としては最後の手段に用いられるものだ。というのも、削除できるのが1度に1つのURLまたはパスであり、また、決定権が完全にグーグルにあるからだ。とはいえ、ここでは選択肢をすべて取り上げておきたい。
技術的な注意点としては、URLの削除をリクエストする前に、そのコンテンツにアクセスすると404エラーが返ってくることを確認するか、robots.txtによるブロック、またはnoindexのメタタグを実施しておくといい。そうしていなくてもURLの削除をリクエストできるが、再度そのURLでクロールしてページにアクセスできた場合、削除は90日間しか続かない。
GWTを使った削除は基本的に、他の方法でグーグル側がどうにも動いてくれない場合の最終防衛策だ。
IV-7 パラメータによるブロック(グーグル)
ウェブマスターツールでは、グーグルに無視してほしいURLパラメータを指定することもできる(グーグルは基本的にこのパラメータを用いてページのインデックス化をブロックする)。
ウェブマスターツールで[サイト設定]>[URLパラメータ]を選ぶと、次のようなリストが表示される。
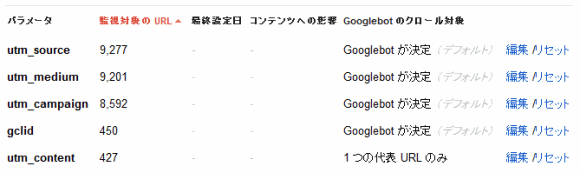
リストには、すでにグーグルが検出したURLパラメータと、各パラメータがどうクロールされるべきかを決める設定が並んでいる。「Googlebotが決定」という設定は、robots.txtやrobotsのメタタグといったほかのブロック方法を反映しているものではない点に留意してほしい。「編集」をクリックすると、以下のような選択肢が表示される。
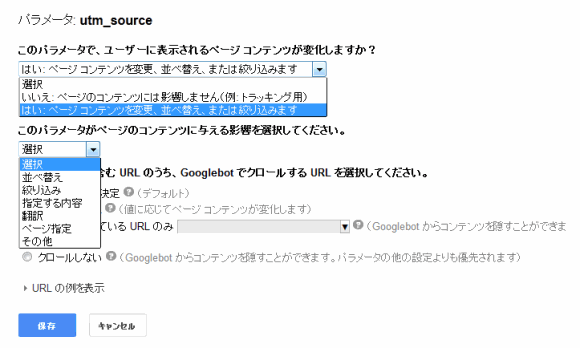
最近グーグルが変更を行ったために、新バージョンは少しわかりにくくなっている気がするが、基本的に「はい」はそのパラメータが重要でインデックス化されるべきものであること、「いいえ」はそのパラメータが重複を示していることを意味する。
このツールは効果がありそうに思える(また手っ取り早い手段にもなり得る)だろうが、優先策としてはやはり推奨できない。グーグル以外の検索エンジンには効果がないし、SEOツールやモニタリングソフトでは検出できない。それに、グーグルによる変更がいつあってもおかしくない。
IV-8 URLの削除(Bing)
Bing Webmaster Center(BWC)には、Googleウェブマスターツールととてもよく似たツールがある。実際には、Bingのパラメータブロックツールのほうがグーグルのツールより先に登場したと思う。
BingにURLの削除をリクエストするには、ウェブマスターセンターの[インデックス]>[URLのブロック]タブで[URLおよびキャッシュのブロック]を選ぶ。次のように表示されるはずだ。

実のところ、BWCの方が選択肢が幅広く、ディレクトリやサイト全体をブロックするよう指示できる。もちろん、最後の選択肢は普通は選ばないものだ。
IV-9 パラメータによるブロック(Bing)
BWCの[インデックス]タブには[URL正規化]という項目がある。この名称からは、Bingが正規化の処理をしてくれるような気がするが、選択肢は[有効にする][無効にする]しかない。
グーグルのツールと同じように、自動的に検出されているパラメータの一覧が表示され、そこでパラメータの追加や修正を行える。
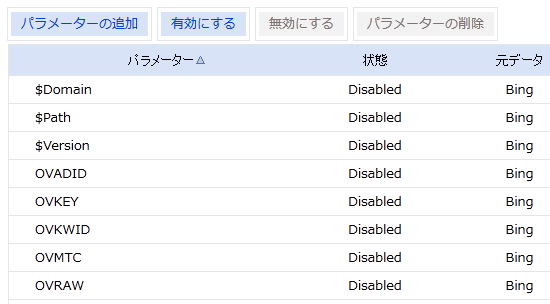
グーグルのGWTと同じく、Bingのツールも最後の手段だと思う。総じて、僕がこれらのツールを使うとすれば、他の方法でうまく行かず、悩みの種となっている検索エンジンが1つだけという場合だけだ。
IV-10 「rel="next"」と「rel="prev"」
グーグルは2011年9月、不完全重複の一形式であるページネーション(ページ分割)された検索結果に対処するための新ツールを公開した。この問題については次のセクションでもっと詳しく説明するが、簡単に言うとページネーションされた検索結果とは、検索結果が複数の塊に分散され、それぞれの塊(たとえば10個の結果)が独自のページ/URLを持つ状況を指す。
「rel="canonical"」によく似た2つの属性を使うことで、ページネーションされたコンテンツ間のつながりをグーグルに伝えることができるようになった。「rel="next"」と「rel="prev"」だ。実装は少し厄介だが、ここでは単純な例を挙げる。

これは検索ボットが検索結果の3ページ目にやってきている場合の例だと考えてほしい。この例では、
- 2ページ目(つまり前のページ)を指す「rel="prev"」属性のタグ
- 4ページ目(つまり次のページ)を指す「rel="next"」属性のタグ
という2つのタグが必要になる。実装が厄介なのは、検索結果はおそらく1つのテンプレートから作られるので、たいていの場合、これらのタグを動的に生成する必要が生じるという部分だ。
当初使ってみたところ、これらのタグはちゃんと機能しているようだが、Bingは対応を表明しておらず、有効性に関して集まっているデータも十分ではない。ページネーションされたコンテンツについては、他の対処方法を次のセクションで簡単に取り上げる。
IV-11 link rel="syndication-source"
グーグルは2010年11月、コンテンツを配信するパブリッシャ向けに2つのタグを導入した。
メタタグによるシンジケーション・ソース(syndication-source)という指示を使うと、転載された記事の配信元を以下のように示せる。

グーグル自身による説明でも、このタグとドメイン名間の「rel="canonical"」をどう使い分けるのかが少し不明瞭だ。また、グーグルは「実験的なもの」としてこのタグを公開したが、それが正式な仕様になったというグーグルの公式な発表はされていないと思う。
さらに、グーグルが最近link rel="standout"というタグを追加したことで、混乱はさらに深まっている。独自のニュース記事を掲載する際に使うものだとされているが、これとsyndication-sourceとの相互作用がよく分からない。
注目には値するが、当てにしてはいけない。
IV-12 サイト内リンクの構造
留意すべき重要な原則がある。重複コンテンツ問題に対処する最良の策は、そもそも初めから重複コンテンツを作らないことだ。もちろん、いつでもそれが可能なわけではないが、対処すべき問題が大量にある場合、サイト内リンクの構造やサイトの構成を再検討してみる必要があるかもしれない。
301リダイレクトやURL正規化タグで重複の問題を修正したら、サイトの他の部分にもその変更を反映させることが大切だ。僕はこれまで、301や正規化タグでページの1つのバージョンを設定したのにサイト内のリンクが非正規のバーションに張られたままだったり、XMLサイトマップに非正規のURLが大量に含まれたりしている例を、驚くほどたくさん見てきた。サイト内リンクは強力なシグナルなので、混乱したシグナルを検索エンジンに送ることは問題を招くだけだろう。
IV-13 何もしない
最後になったが、検索エンジンに解決を任せるという方法もある。実際、グーグルは長年にわたってこのやり方を推奨している。だが、僕の経験から言うと、残念ながら良い結果になることはほとんどない。規模の大きなサイトだとなおさらだ。
とはいえ、重複コンテンツが必ずしも大きな問題を引き起こすとは限らないことと、グーグルが大きな影響を及ぼすことなく一部の重複コンテンツをフィルタリングできる例も確かにあることは、指摘しておくべき重要な点だろう。
単発的な重複コンテンツが少しだけあるという場合、そのままにしておくというのは十分に有効な選択肢になる。
重複コンテンツ問題に対処する手段の紹介がようやく終わった。次回からはこれを踏まえて、重複コンテンツの具体例と、それにどうやって対処するかを紹介しよう。


この記事は、Daily SEOmoz Blog に掲載された以下の記事を日本語訳したものです。
原文:「Duplicate Content in a Post-Panda World」 by Dr. Pete (2011/11/16)
必見! Facebookいいね! 人気記事
最近(過去90日間)の記事で、Facebookの「いいね!」が多かった記事をお見逃し無く。

ソーシャルもやってます!