「グーグルが検索順位を決める要因200個の完全版リスト」という都市伝説(前編)
グーグルが検索結果において順位を決定するのに使う要因は、200個以上あると言われる。さて、それらの情報を、SEO担当者としてはどう扱うべきなのか。本当に正しい検索順位決定要因は何なのか、影響する要因の数はいくつなのか、SEOのプロが「検索エンジンが順位を決定する要因」について熱く解説する。
グーグルが検索順位を決定する要因200個の完璧なリストなど存在しない
グーグルが検索順位を決定する要因には200個あるが、その200個の完全版のリストが手に入った。
そう告げられたとしたら、スタートレックのピカード艦長は、次のGIFアニメのように反応するだろう。
つまり、賢明なるピカード艦長は、顔を手のひらで覆って立ち去るだけだ。
ピカード艦長のこの反応を誰が責められようか。
検索順位を決定する要因200個の完璧なリストなど存在しないことは、だれもが知っている。
あなただってそうだろう。ではなぜいまだにBuzzsumoの検索結果に次のようなものが見られるのだろうか。
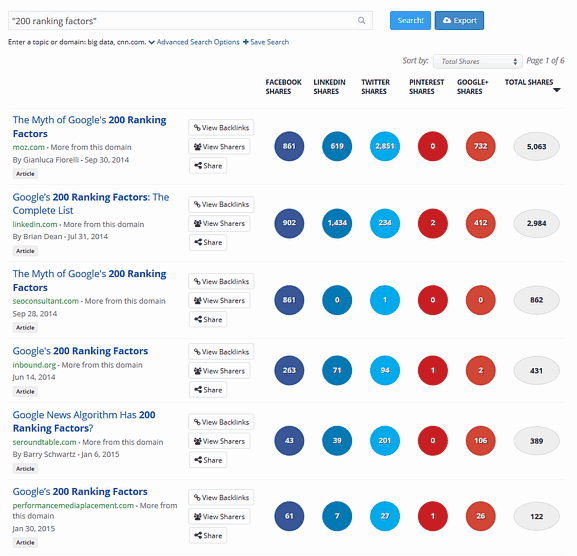
なぜ既存の「要因200個」というコンテンツがダメなのか
話を進める前にちょっと断っておきたい。この記事は、いわゆる「200要因の完全リスト」を作って公開している人たちを攻撃しようというものではない。そのネタで効果的なリンクベイトを作って500以上ものルートドメインからのリンクを獲得したディーン氏を、僕はすごいと思う。
僕がこの記事を書くのは、そうしたリストがまったく意味がなく危険でさえあること、また、グーグルの検索順位決定要因の決定版である完璧な「リスト」というものが存在しないことを、とりわけ新しい世代のSEO担当者にわかってほしいからだ。
しかも、そうしたリストに並ぶ要因には次のようなものが含まれている。
- 都市伝説でしかない
- 並べられている要因に相関関係はあるが因果関係ではない
- 数を200にするために入れられただけ

都市伝説の起源はグーグル? でも実際にはその50倍も……
実は、「グーグル検索順位決定要因200」の都市伝説がどのように生まれたのか僕は知らなかったのだが、SEO仲間であるジョルジオ・タバニティ氏が教えてくれた。
グーグルが200個の検索順位決定要因を使っていると最初に明言したのは、2006年5月10日の「Press Day」だった(マット・カッツ氏による中継ブログも参考になるだろう、その後に起こったさまざまなことが明らかにされている)。

正確な文言が「200以上の検索順位決定要因」であることをみても、「200」という数字が概数であり、グーグルのアルゴリズムが複雑であることをジャーナリストに説明するために使われた可能性があることがわかる。聴衆がプレスではなく情報技術者だったとしたら、アラン・ユースタス氏は他の言い回しを使ったのではないだろうか。
「グーグルの検索順位決定要因200を発見した」という主張が馬鹿げたものである証拠がもう1つある。2010年にマット・カッツ氏その人が、グーグルの順位決定要因は200個以上あり、しかも各要因に最大50のバリエーションがあると明言したのだ。

「インデックス化」と「順位付け」の用語の違いを、正確に説明できるのか?
そもそも、「順位付け」と「インデックス化」という言葉の意味するところを、あなたは正しく理解できているだろうか。
というのも、たくさんのSEO担当者がこの2つの言葉を同義語として使っているのをよく見るからだ。本当は、検索エンジンの仕組みのなかのまったく異なる段階における全然別の概念であるのに。
検索エンジンの仕組みには4つの段階があって、それらは相互に連動・依存している。インデックス化はそのうちの1つだ。
- クローリング
- 構文解析
- インデックス化
- 検索
インデックス化とは、語や語句に関連するウェブ上のリソースの発見と調査を行う処理だ。この動作を行うのはあくまで検索エンジンであり、SEO担当者ではない。SEO担当者にできることがあるとしたら、サイトの最適化を手伝うことくらいのものだ。
エンリコ・アルタヴィッラ氏が的確に説明してくれているように、「インデックス」は、ある検索クエリやクエリを構成する語や語句に対する答えとしてどのリソースを提案するかを判断するのに使われるものであり、提案の順番を決めるものではない。順位付けは別の段階だ。
順位付けは、検索エンジン4つの段階のなかでは、クローリングとも構文解析ともインデックス化とも別の処理で、4段階のうち最後である「検索」のうちでも、さらに最終段階に処理される。
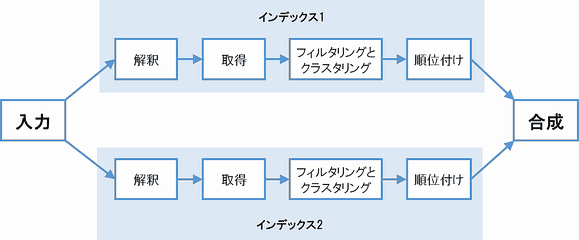

検索段階では文脈が大きく関与し、ほぼすべての局面においてユーザー特性とデバイス特性が考慮される。
上の図にあるように、検索段階は、4つの明確に別れたステージで構成されている。:
入力された検索クエリの解釈 ―― ハミングバードはこのステージで影響を及ぼしている可能性が高い。というのも、グーグルは入力をさらによく理解できるように検索クエリの修正や拡張を施したうえで次のステージに移るからだ。
インデックスからのドキュメントの取得 ―― 「noindex」などのコマンドはここで考慮される。
フィルタリングとクラスタリング ―― 入力を解釈して、対応するドキュメントをインデックスから取得したら、パンダなどのスパムフィルターを適用する。また、セーフサーチのフィルターや忘れられがちなプライベート検索レイヤー(個別化)など、検討頻度の低いものもここで適用される。
順位付け ―― グーグルが検索順位決定要因を適用するのは、この時点であって、これ以前ではない。それに、順位決定要因は次のようなグーグルによるインデックスの種類ごとに検討され、考慮されるべきものだ(上図における「インデックス1」「インデックス2」などそれぞれ)。
- ユニバーサル検索
- 画像検索
- ローカル検索
- その他
また、検索結果ページ(SERP)のコンテンツとレイアウトは使用デバイスによるところが大きいことも忘れてはならない。

グーグルの検索順位決定要因に関して解説するこの記事は、前後編の2回に分けてお届けする。後編では、世の中で語られている「順位の決定要因」でどんなものが間違っているか、具体的に例を10個挙げて解説し、こうした情報のうち、参照して問題ないものやそうした情報の扱い方を解説する。→後編を読む


この記事は、Moz Blog に掲載された以下の記事を日本語訳したものです。

原文:「The Myth of Google's 200 Ranking Factors」 by Gianluca Fiorelli (2014/09/30)
必見! Facebookいいね! 人気記事
最近(過去90日間)の記事で、Facebookの「いいね!」が多かった記事をお見逃し無く。

ソーシャルもやってます!