SEOの知識にクイズで挑戦! あなたは正解できる? robots.txt初級+中級【SEO情報まとめ】

知っておいて損はない(でもちょっとマニアック)SEOの知識にクイズで挑戦! あなたは仕様を理解してrobots.txtを書き、Googlebotをちゃんとコントロールできるか!?
ほかにも、JavaScriptレンダリング最新情報、SEOでの重要度が高まっている構造化データ、SEOの「ペナルティ」、グーグルのAMPの扱いなどなど、今週もSEOやサイト運営に役立つ、次のような情報をまとめてお届けする。
- GooglebotのJavaScriptレンダリングに関する2つの最新豆知識
- リッチリザルト テストが正式版になり構造化データテストツールは引退へ
- 動画の構造化データに関するアップデート
- グーグルに送ったスパムレポートはどのように使われるのか?
- SEOの「ペナルティ」は古い考え方!?
- グーグルが新型コロナ対策に新型ツールで尽力
- グーグルがAMPを捨てる日は来るのか?
- 7月のオフィスアワー開催――ネイティブLazy-loadのフォールバックやHTTPSがランキングに与える影響、ソフト404修正など
- Google社員とBing社員がタッグを組んでSEOを語る
- ついにSafariが画像フォーマットとしてWebPをサポート! ウェブページの表示高速化に期待
- Googlebotはショッピングカートに商品を追加する。カゴ落ち率が悪化する可能性あり
今週のピックアップ
SEOの知識にクイズで挑戦! あなたは正解できる? robots.txt初級+中級
1つ間違えた(汗 (Gary Illyes on Twitter) 海外情報
robots.txtに関するクイズを、グーグルのゲイリー・イリェーシュ氏がツイッターで投稿している。提示した記述だとクロールがどうなるかを2択から選ぶ。ヘルプを見たりツールを使ったり検索したりせずに挑戦してみてほしい。
User-agent: *
Disallow: /
Allow: /- 選択肢1. クロールをすべて禁止
- 選択肢2. クロールをすべて許可
Q2 このrobots.txtをGooglebotはどう解釈する?
User-agent: Googlebot
Allow: /
User-agent: *
Disallow: /
- 選択肢1. Googlebotのクロールを許可
- 選択肢2. Googlebotのクロールを禁止
正解を見る(ここをクリックで展開):
Q1の正解は「選択肢2. クロールをすべて許可」
Q2の正解は「選択肢1. Googlebotのクロールを許可」
解説する。これは、どちらも「同じパスに対して複数の指定がある場合」のルールだ。
Q1の解説
同じパスに対して、同じユーザーエージェント名指定で
Disallow(禁止)とAllow(許可)を指定している場合は、Allowが優先される(こちらを参照)。Q1では「
/」のパスが対象。「
User-agent: *」ですべてのユーザーエージェントを対象として、「Disallow」と「Allow」を指定している。この場合、
Allowと判断される。Q2の解説
同じパスに対して、異なるユーザーエージェント名を指定して
Disallow(禁止)とAllow(許可)を指定している場合は、合致する最も限定的なユーザーエージェントに対するルールが適用される(こちらを参照)。Q2では「
/」のパスが対象。「
User-agent: Googlebot」でGooglebotを対象に「Allow」を指定している。「
User-agent: *」ですべてのユーザーエージェントを対象に「Disallow」を指定している。この場合、より限定的なGooglebotを対象とした指定が優先されるので、Googlebotは
Allowと判断する。
さて、あなたは2問とも正解できただろうか? 最終結果を見ると、Q1は正解が若干少なかった(正解者が約48%)。Q2は約60%が正解していた。お恥ずかしながら筆者はQ1を間違えた(汗
Try answering without the help of a tool. How will this affect crawling:
— Gary 鯨理/경리 Illyes (@methode) July 2, 2020
User-agent: *
Disallow: /
Allow: /
The previous poll was fun, so here's another one. Once again, try to answer without the help of a tool.
— Gary 鯨理/경리 Illyes (@methode) July 7, 2020
How will this affect Googlebot specifically:
User-agent: Googlebot
Allow: /
User-agent: *
Disallow: /
- SEOがんばってる人用(ふつうの人は気にしなくていい)
- ホントにSEOを極めたい人だけ
グーグル検索SEO情報
GooglebotのJavaScriptレンダリングに関する2つの最新豆知識
スピードアップしてる (Martin Splitt on Twitter) 海外情報
検索におけるJavaScriptの処理に関するマーティン・スプリット氏からの情報を2つ紹介する。
GooglebotのJSレンダリングは遅くない
「JavaScriptのレンダリングをGooglebotが完了するまでには、それなりに時間がかる」という認識の人が多いのではないだろうか。実際に、昔はそのとおりで、特にレンダリング処理の順番待ちに時間がかかっていた。そのため新鮮さが重要なニュース記事などはコンテンツをJavaScriptで生成すると、検索結果に出るころには古くなっていることがあり得た。
しかし現在は、この問題はかなり改善されている。レンダリングの処理にかかるまでの待ち時間は中央値で5秒程度になっており、全体の90パーセントは数分以内に処理が開始されているのだという(少なくとも10分以内)。
noindex指定はJSでも大丈夫だが初期HTMLに注意
JavaScriptでページ内容をつくるタイプのページでのnoindex指定の扱いも進化している。次のいずれの状態でも、適切にnoindexを認識してくれる:
HTMLの状態でnoindexが入っていれば、そのページはインデックスされない。
初期HTMLにはnoindexが入っていなくても、JavaScript処理でnoindexを挿入すれば、Googlebotはnoindexを認識してインデックス処理を行わない。
ただし注意が必要な点もある。初期HTMLにnoindexが入っていて、JavaScriptでnoindexを削除する流れの場合、そのページはインデックスされない。初期HTMLでnoindexを検出するとGooglebotはレンダリングを実行しないためだ。
- ホントにSEOを極めたい人だけ
- 技術がわかる人に伝えましょう
リッチリザルト テストが正式版になり構造化データテストツールは引退へ
Google検索と同じ仕組みでテスト (グーグル ウェブマスター向け公式ブログ) 国内情報
リッチリザルト テスト ツールがすべてのリッチリザルトの検証に対応したことを、グーグルがアナウンスした。
これまではリッチリザルト テストはベータ版としての提供で、検証できないリッチリザルトがあった。すべてに対応したことで、今後はリッチリザルト テストを利用するようにグーグルは推奨している。
公式ブログ記事が紹介しているリッチリザルト テストの改善点は次のとおりだ。
- ページで指定しているマークアップに有効な検索機能を表示
- 動的に読み込まれる構造化データ マークアップをより効果的に処理
- モバイル版ページとパソコン版ページの両方の検索結果をレンダリング
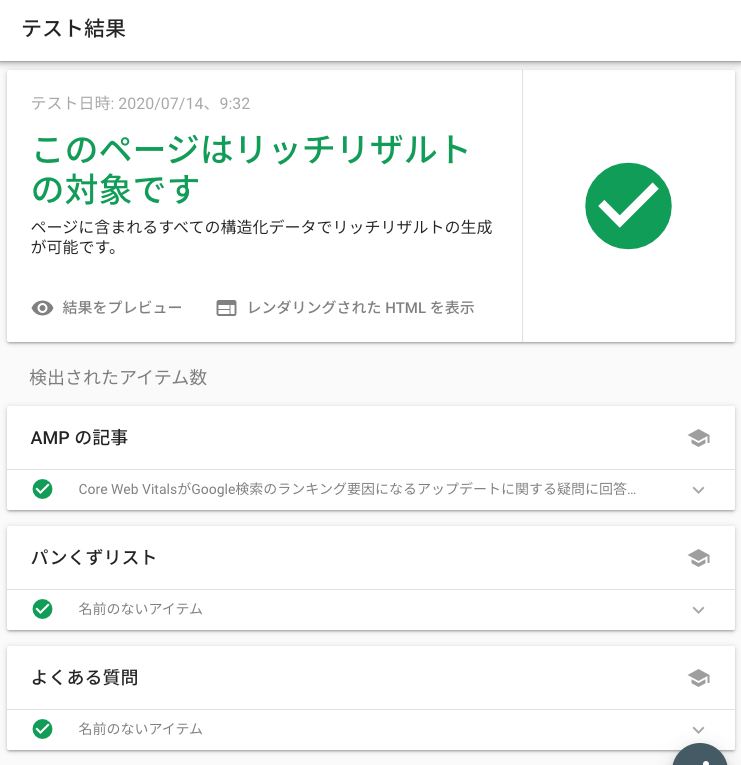
リッチリザルト テストはGoogle検索が利用するのと同じレンダリングの仕組みを使っているので、実際の検索での状態を確かめられるのも強みだ。
また、リッチリザルト テストが正式版になったことにともない、構造化データ テストツールは提供を終了する。当面は利用できるようだが、遅かれ早かれ廃止となる。
- 構造化データがんばってる人用(ふつうの人は気にしなくていい)
動画の構造化データに関するアップデート
embedUrlかcontentUrlのプロパティが必要に (Google Devs Japan on ツイッター) 国内情報
動画の構造化データ(VideoObject)をマークアップしているサイトのウェブ担当者が関係するアップデート情報をお伝えする。
📺 Search Console のレポート機能の変更についてお知らせします。
— Google Devs Japan (@googledevjp) July 10, 2020
動画構造化データを使用している場合、レポートがドキュメントに一致するように変更されたため、VideoObject で embedUrl も contentUrl も使用されていないと警告が表示されるようになりました。詳細↓https://t.co/11g93gQi6D
embedUrlまたはcontentUrlのいずれかのプロパティを追加していないと警告が出るようになった。今の状態でどちらも追加していなければ修正しておこう。
- 動画の構造化データをマークアップしているすべてのWeb担当者 必見!
- 技術がわかる人に伝えましょう
グーグルに送ったスパムレポートはどのように使われるのか?
スパム対策アルゴリズムの改善にのみ利用 (グーグル ウェブマスター向け公式ブログ) 国内情報
検索結果でスパムを発見した際は、スパムレポートからグーグルに通報できる。このようにしてユーザーから送られてきたスパムレポートの利用に関する説明をグーグルは更新した。
端的に言うと、スパム検出アルゴリズムの改善のためだけにスパムレポートを現在は利用しているとのことだ。スパムレポートによって通報されたサイトを、グーグル社内のスパムチームの人間がチェックして手動の対策を与えることはない。
※Web担編中:元記事では「スパムレポートの大半は手動による対策で処理されることになりますが」という記載があるが、これは以前のことで、現在はアルゴリズム改善のためだけに利用しているとのことだ。
このようにしている理由は、アルゴリズムで自動処理したほうが大規模にスパムに対応できるからだ。人力での対応には限界がある。
とはいえ、アルゴリズムはすぐに改善されるわけではないので、スパムサイトを通報しても検索結果からすぐに姿を消すことはないかもしれない。そうなると、通報が無意味だと考える人もいそうだ。しかし、長い目で見れば、同類のスパムの排除にスパムレポートは貢献する。即座の改善がなかったとしても、アルゴリズム改善のためにスパムを発見したら通報しよう。
- SEOがんばってる人用(ふつうの人は気にしなくていい)
【SEO情報まとめ】")






鈴木 謙一(すずき けんいち)
「海外SEO情報ブログ」の運営者。株式会社Faber Companyの執行役員(Search Advocate)。
海外SEO情報ブログは、SEOに特化した日本ではもっとも有名なSEO系ブログの1つ。米国発の最新のSEO情報を中心に、コンバージョン率アップやユーザーエクスペリエンス最適化のための施策も取り上げている。
正しいSEOをウェブ担当者に習得してもらうために、ブログでの情報発信に加えて所属先のFaber Companyでは、セミナー講師や講演スピーカーを主たる役割にしている。
必見! Facebookいいね! 人気記事
最近(過去90日間)の記事で、Facebookの「いいね!」が多かった記事をお見逃し無く。

ソーシャルもやってます!