グーグル動画検索ではYouTubeが圧倒的に有利。このデータにマーケターはどう動くべきか
検索210万件と動画76万6000本を調査したところ、グーグルの検索結果1ページ目に表示される動画カルーセル全体の94%をYouTube動画が占めており、競争の余地がほとんどないことがわかった。
「動画は好きだが、あまり頻繁に見るわけではない」、そんな人でも、YouTubeのことは知っている。そう、グーグルが2006年に買収した動画サービスだ。
君はグーグル検索ユーザーとして、YouTubeの動画を他のどのサイトからの動画よりもよく目にすると感じているかもしれないが、これはデータで裏付けられるだろうか?
ウォール・ストリート・ジャーナルは2020年7月の記事で、「検証によりグーグルの検索結果でYouTubeが特に優位にあることが確認された」と報じたが、この検証では動画98本を手作業で選び、YouTubeと他のプラットフォームを比較している。
僕たちは、2020年10月初旬に取得したGoogle.com(米国サイト)のデスクトップ検索200万件超のデータセットを使用して、検索結果1ページ目の動画カルーセルに表示される動画25万本以上を抽出できた。2020年の時点で、ほとんどのオーガニック動画検索結果は、次のようなカルーセルで表示される。

このカルーセルは、「How to be an investor」(投資家になる方法)を検索した場合に表示されたものだ(最初のステップは、トランクケースいっぱいの資金を工面することだ)。右端の矢印に注目してほしい。現時点で、検索ユーザーは最大10本の動画をスクロールして確認できる。調査では10本すべての動画を追跡したが、本レポートの大部分では最初に表示される3本に焦点を当てる。
YouTubeはどれほど優位にあるのか
ちなみに、グーグル検索結果には多くのYouTube動画が表示されるが、僕たちのデータセットで動画カルーセルに表示される3本を見ると、YouTube動画はどれほど優位にあるのだろうか? その内訳を次に示す。


(カルーセルの位置別、2020年10月、動画25万本以上)
最初の3本の動画枠を見ると、YouTubeのプレゼンスは驚くほど徹底しており、
- 1本目: 94.1%
- 2本目: 94.2%
- 3本目: 94.2%
だった。各カルーセル枠で2位と3位になったのはカーンアカデミーとFacebookで、Facebookは4本目以降の動画枠でもシェアを獲得していた。
シェアが最も多いサイトから2番目に多いサイトとの間で数値が大幅に低下しているのは明らかで、YouTubeのプレゼンスは10本の枠すべてで94.1~95.1%の間にあった。
カルーセルに表示されるすべての動画のうち、僕たちのデータセットで上位10位までに入ったサイトは以下のとおりだ:
- YouTube(94.2%)
- Khan Academy(1.5%)
- Facebook(1.4%)
- Microsoft(0.4%)
- Vimeo(0.1%)
- Twitter(0.1%)
- Dailymotion(0.1%未満)
- CNBC(0.1%未満)
- CNN(0.1%未満)
- ESPN(0.1%未満)
検索スパイダーの仕組みに技術的制約があるため、多くのFacebook動画およびTwitter動画はログインしないと視聴できず、グーグルには表示されないことに注意してほしい。とはいえ、動画カルーセルで2位から10位の上位サイト(動画コンテンツに多額の資金を投じている巨大ブランドも含まれる)を合計しても、表示される動画全体のわずか3.7%しかない。
ハウツー動画についてはどうか?
どう呼べばいいかわからないのだが、「How to…」(~する方法)というクエリは動画検索で人気の形態となっており、必然的にHGTVなどニッチなサイトに適している。
次に示すのは、「how to organize a pantry」(パントリーを整理する方法)を検索した結果の動画カルーセルだ。

検索結果全体ではYouTubeが圧倒的だったが、こうしたニッチなクエリでは比較的多様なウェブサイトが表示されるだろうか?
僕たちのデータセットで、「How to…」で検索して動画カルーセルが表示されたのは4万5000件余りにすぎなかった。枠ごとの上位3本のサイトの内訳は次のとおりだ:

(カルーセルの位置別、2020年10月、動画4万5000件余り)
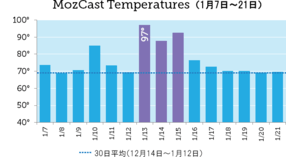
僕たちのデータセットでは、ハウツーというニッチなクエリでもYouTubeはさらに優位にあり、表示される3つの枠でそれぞれ97~98%を占めた。カーンアカデミーが2位、マイクロソフト(具体的にはマイクロソフトのサポートサイト)が3位に入った(ただし、3つの枠すべてで1%未満)。
これは偶然にすぎないのか?
この分析の大部分は、2020年10月初旬に取得したスナップショットのデータを基にしている。グーグルが頻繁に変更を加え、1年間に多くのテストを実施していることを考えると、僕たちは特に例外的な日を選んだにすぎないという可能性はないだろうか? それを確かめるため、僕たちは2020年の毎月1日にカルーセルのすべての動画でYouTubeが表示される割合を調べた。

YouTubeの優位性は2020年を通じてかなり安定しており、僕たちのデータセットでは92.0~95.3%の範囲を行ったり来たりしている(実際、1月以降はわずかに増加した)。これが一時的なものでも、特に最近の状況でもないことは明らかだ。
たとえ大量のデータセットでも、グーグルの結果を調査するうえでもう1つの課題となるのは、サンプリングにバイアスがかかっている可能性だ。検索結果において真に「無作為」のサンプルというものはないが(詳細は付録Aを参照)、僕たちには幸いなことに長期の履歴を含む2つ目のデータセットがあった。
このデータセットにはわずか1万件のキーワードしか含まれていないが、Google広告の業種カテゴリを均等に表すよう特別に設計されていた。僕たちは10月9日、このデータセットから2390件の動画カルーセルを取得できた。その内訳は次のとおりだ:

(カルーセルの位置別、長期の履歴を含むデータセット、動画2390件)
カルーセル枠別に上位3つのサイトは、キーワード200万件のデータセットと同じだったほか、YouTubeの圧倒的優位性はさらに高かった(94%から96%に上昇)。この調査で測定された検索結果におけるYouTubeの優位性は、1日または1件のデータセットに限定された偶然の現象ではないと僕たちは確信している。
競争環境はどれほど公平か?
YouTubeは不当に優位な地位を得ているのだろうか? 「公平性」は定量化するのが難しい概念なので、グーグルの見方を探ってみよう。
グーグルの主要な主張は、次のようなものだろう:
YouTubeが動画検索で圧倒的なシェアを有しているのは、同サイトが動画で圧倒的なシェアを占めているのが理由だ。
残念ながら、動画共有サービス全体について信頼できる数字を明らかにするのは難しく、ソーシャルプラットフォームの場合は特に難しい。YouTubeが巨大なサイトであることに疑いの余地はなく、米国ではソーシャルメディアに投稿されていない公開動画の大多数をホスティングしていると思われる。しかしそれでも、いくら巨大サイトとはいえ94%のシェアは高すぎるように見える。
さらに大きな問題は、この圧倒的優位性が無限に継続し得ることだ。
ここ数年、YouTubeで動画を配信したり、YouTubeチャンネルを開設したりする大手企業が増えている。その理由は、より小規模なプラットフォームや独自のサイトで配信するよりもグーグル検索結果に表示されやすくなるからだ。
より技術的な面におけるグーグルの主張は、動画検索アルゴリズム本来の性質としてYouTubeを優先することはないという点だ。
僕は検索マーケターとして、この主張を厳密に捉えることを学んだ。これは、アルゴリズムのなかに、「YouTubeの動画ならば上位に表示する」といった処理は含まれていないということだろう。
狭義に考えるなら、グーグルは真実を語っていると僕は思う。
ただし、グーグル検索とYouTubeが共通の基盤や内部構造の多くを共有している事実は否定できない。そうしたものが、太刀打ちできない優位性をもたらしている可能性がある。
たとえば、グーグルの動画アルゴリズムは速度を重視しているかもしれない。これは理にかなっている。なぜなら、読み込みの遅い動画は顧客体験が悪く、そうした動画を検索結果に表示すると最終的に全体としての検索体験が悪化し、グーグルの落ち度のように見えるからだ。
当然ながら、グーグルがYouTubeを直接傘下に収めているということは、グーグルはYouTubeのデータに瞬時にアクセスできるということだ。現実的に考えて、たとえ数十億ドルを投資したとしても、グーグルと直接つながっているサイトより高速な体験をいかにして競合が生み出せるだろうか?
同様に、YouTubeのデータ構造は当然ながら、簡単に処理して整理できるようグーグル向けに最適化される。これには内部の知識を活用するが、こうした知識はすべてのサイトが平等に利用できるものとは言えないかもしれない。
2020年時点での結論
現時点での結論は、次のとおりだ。
Google検索においてYouTubeが圧倒的優位にあることは事実だ。マーケティングの視点から見ると、万全の準備をしてYouTubeから得られそうな利点を活用する以外に、選択肢はほとんど残されていない。
YouTubeのシェアが低下するとみるべき理由はなく、少なくともこの業界にとってパラダイムシフトとなる創造的破壊がない限り、YouTubeの優位はさらに高まるだろう。
データセットとその解釈の仕方に関する知識を共有してくれたバンクーバーチームのエリックH.とマイケルG.、そして僕を信頼してAmazon Athenaでデータの宝庫にアクセスできるようにしてくれたエリックとロブL.に心から感謝したい。
付録A:データと手法
この調査で使用したデータの大部分は、2020年10月初旬、米国のGoogle.comデスクトップ検索結果200万件余りから収集したものだ。若干の重複排除とクリーンアップを経て、このデータセットから、1ページ目に動画カルーセルが表示される検索結果25万8000件が得られた。これらのカルーセルには、全体で210万件の動画/URLと、最初に表示される動画76万7000件(グーグルは、スクロールしなくてもカルーセルごとに最大3本の動画が表示されるようにしている)が含まれていた。
ハウツー動画の分析はこれより少なく、明確に「how to」という言葉で始まるキーワード4万5000件のデータセットに基づいている。どちらのデータセットも無作為に選択したサンプルではなく、特定の業種やバーティカルに偏っている可能性がある。
補足調査用のデータセット1万件は、特に調査用データセットとして構成されたものであり、Google広告の主な20業種のカテゴリから均等に取得している。このデータセットは、競争の激しいさまざまなキーワードが含まれるよう特別に設計された。
なぜ、真に無作為抽出したサンプリングを使わないのか? 教科書的な説明にとらわれずに考えると、真に無作為なサンプルというものは滅多に実現できないが、理論上は可能だ。たとえば、米国の成人を無作為に抽出するのは非常に難しいが(電話をかけるかメールを送った途端にバイアスがかかる)、少なくとも、特定の時点において米国の成人人口が個々の人間の有限集合であることはわかっている。
グーグル検索は、これとは異なる。検索は有限集合ではなく、言葉でできた雲のようなもので、これが1000分の1秒ごとに何もないところから検索ユーザーによって生み出されている。グーグル自身の言葉を借りると、次にような状態だ:
グーグルでは年間に数兆もの検索が行われています。しかも、グーグルで行われる検索のうち、毎日15%は、これまでに一度も検索されたことのない、まったく新しいクエリです。
検索数が数兆件に上るだけでなく、それが1分ごとに変化している。
僕たちは最終的に、可能な場合は大量のデータセットを利用して、いかなるデータセットにも欠点があることを理解するよう努め、複数のデータセットで調査を再現している。本調査は、2つのまったく異なるデータセットおよび第1のセットの根幹部分から作成した第3のセットで再現し、2020年の複数の日で検証した。

~「ヒュッゲ」なモードの顧客のために")



この記事は、Moz Blog に掲載された以下の記事を、Mozの許諾を得て日本語化したものです。

原文: 「YouTube Dominates Google Video in 2020」 by Dr. Peter J. Meyers (2020/10/14)
必見! Facebookいいね! 人気記事
最近(過去90日間)の記事で、Facebookの「いいね!」が多かった記事をお見逃し無く。

ソーシャルもやってます!