リンクの否認ツールが効果を発揮するには条件があるのか?
海外のSEO/SEM情報を日本語でピックアップ
リンクの否認ツールが効果を発揮するには条件があるのか?
再審査リクエストかアルゴリズム更新 (Above the fold)
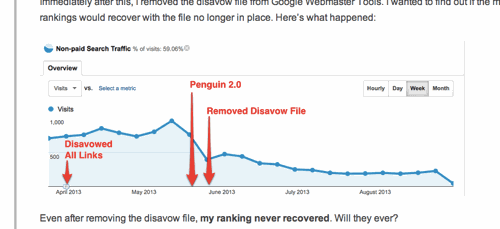
リンクの否認ツールを利用して、サイトに張られたバックリンクをすべて否認したら何が起こるだろうか?
そんな実験の結果を、こちらの記事ではレポートしている。
結果を簡潔にまとめると、以下のようになる。
- しばらくは検索順位にも検索トラフィックにも何の変化もなかった
- ペンギンアップデート2.0の実施直後に検索トラフィックが大きく減った
- トラフィックが減ったすぐ後に否認ファイルを削除したが、3か月ほど経過した今でもトラフィックは回復していない

この結果と他のウェブマスターから聞いた話を基に、実験者は次の可能性を疑っている。
再審査リクエストを送信するかペンギンアップデートのような大きなアルゴリズム更新が発生しないと、リンクの否認は効果が出ない。
検証事例がこの1例しかなく、大きなアルゴリズム更新がペンギン2.0の1つしか実行されていないためデータ不足であることは、実験者も認めている。
果たして真相はどうなのだろうか。同じような経験をしていたら、ぜひ教えてほしい。
なお、実験対象のサイトは不正なリンク集めを一切やっておらず、完全に自然発生したバックリンクだけが集まっていたとのことである。
ウェブマスターツールでサイトが未確認になる原因
Googlebotがいつでもきちんとアクセスできるようにしておくこと (Google Webmaster Help Forum)
グーグルウェブマスターツールに登録したサイトの確認状態が未確認になる原因と、確認手段をそのままにしておくことの重要性について、グーグルのジョン・ミューラー氏が説明した。
(ウェブマスターツールでのサイト所有の)確認のための要素(ファイルなど)が所定の場所にあるかどうかを、私たちは定期的にチェックしている。もし確認できなかった場合は、ウェブマスターツールでサイトを「未確認」の状態にするだろう。
たとえば、サイトを登録するときだけ確認のための要素を設置し、後から削除したとしたら、「未確認」状態になることがある。
「未確認」になるもう1つの可能性は、散発的にGooglebotがサイトへ適切にアクセスできなくなってしまい、結果として、確認要素を確かめられない状態がときおり発生するケースだ。
このケースでは、ウェブマスターツールのクロールエラーレポートで、似たようなエラーを発見できるはずだ。
こんなふうに散発的にアクセスできないことが原因で問題が起きないよう確かに取り組んでいるが、クロール頻度が低下することがありうる。すると、今度は、新しいコンテンツや更新したコンテンツのクロールとインデックスに支障をきたすこともある。
ウェブマスターツールにサイトを登録したときに利用したサイトの確認手段は、その後もきちんと保持しておき、かつGooglebotが確実にアクセスできるようにしておこう。
意外と知られていない、Googlebotのクロール速度の問題を報告する方法
普通は自動で最適に調整されているからね (Google Webmaster Help Forum)
Googlebotのクロール速度は、通常、最適な速度に自動的に設定されている。しかしウェブマスターツールで手動の変更も可能だ。またクロール速度の変更はドメイン名レベルでのみ実行できる。
これらは知っていて当然のことだ。しかし次の2つは案外知られていないのではないだろうか。
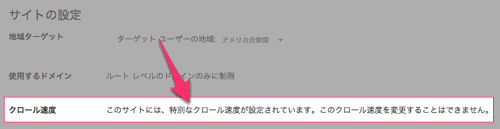
特別なクロール速度
特別なクロール速度は、グーグル側において手動で、クロール速度が最適になるように設定されている。
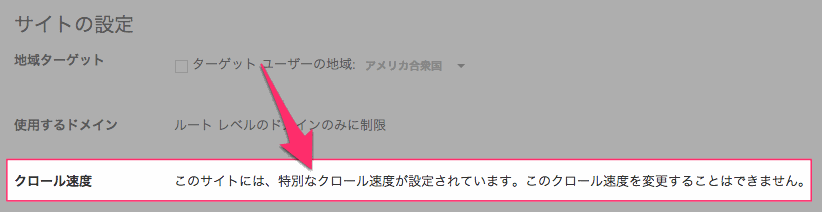
問題の報告
クロール速度が不適切だと判断した場合は、その旨をグーグルに直接フィードバックできる。
右上の歯車アイコンから[サイトの設定]>[クロール速度]セクションの右にある「詳細」をクリックすると出てくる「Googlebotに関する問題を報告」をクリックする。するとフォームが表示され、詳細を報告できる。

1つ目は知らなくてもどうということはないが、2つ目は知っておくとよさそうだ。Googlebotのクロール速度に問題を感じているようであれば(クロールが頻繁すぎてサイトの反応が遅くなるなど)、フィードバックを送るといいだろう。
重複コンテンツにならないように同じコンテンツをPDFとHTMLの両方で公開する方法
HTTPヘッダーでrel=“canonical”を返す (WebmasterWorld)
下のような質問がWebmasterWorldフォーラムに投稿された。
PDFで電子書籍や白書をいままでたくさん公開してきた。どれも質が高いものばかりだ。
同じ内容をそのままウェブページ(HTML)としてもサイトで公開したいのだが、たとえばパンダアップデートによって重複コンテンツ扱いされたりしないだろうか。
グーグルはPDFもしっかりとインデックスする。したがって、PDFとHTMLで同一コンテンツを公開したら重複コンテンツ扱いされる可能性が確かにある。
robots.txtでPDFをブロックしたらどうかというアドバイスも出ているが、最も適切なのはHTTPヘッダーでrel="canonical"を返し、PDF版をHTML版に正規化することであろう。PDFではHTMLタグとしてrel="canonical"を指定できないので、代わりに、そのPDFファイルへのアクセスに対して、HTTPヘッダーでcanonicalを指定するのだ。
HTTPヘッダーでrel="canonical"を返す仕組みは過去にこのコーナーでピックアップしているので、そちらを参照してほしい。
GoogleアナリティクスがIE 8にサヨナラを告げる
残り3か月 (Analytics Blog)
Googleアナリティクスの英語版公式ブログが、マイクロソフト製のInternet Explorer 8(IE 8)のサポートを2013年いっぱいで打ち切ることを発表した。
勘違いしてならないのは、IE 8のアクセスをGoogleアナリティクスが取得できなくなるということではなく、GoogleアナリティクスのレポートをIE 8で見られなくなるということだ。
新しい機能を今後Googleアナリティクスで利用可能にすることが狙いだ。IE 8をサポートし続けると、それが新しいテクノロジーの採用の足かせになってしまうのだ。
Googleアナリティクスを利用するウェブ担当者が、IE 8のような古いブラウザを使い続ける理由はないであろう。社内でIE 8を利用していたとしても、Googleアナリティクスを使うときは最新のブラウザを使えば済む。
 SEO Japanの
SEO Japanの
掲載記事からピックアップ
レスポンシブ・ウェブデザインとリンクの否認ツールについての記事を今週はピックアップ。
- レスポンシブWebデザインがユーザー体験に最適化できていない5つの実例
SEOではなくユーザー体験を考えよ - Googleのリンクの否認ツールに関するデマを一刀両断
グーグル社員からの説明まとめ


鈴木 謙一(すずき けんいち)
「海外SEO情報ブログ」の運営者。株式会社Faber Companyの執行役員(Search Advocate)。
海外SEO情報ブログは、SEOに特化した日本ではもっとも有名なSEO系ブログの1つ。米国発の最新のSEO情報を中心に、コンバージョン率アップやユーザーエクスペリエンス最適化のための施策も取り上げている。
正しいSEOをウェブ担当者に習得してもらうために、ブログでの情報発信に加えて所属先のFaber Companyでは、セミナー講師や講演スピーカーを主たる役割にしている。
必見! Facebookいいね! 人気記事
最近(過去90日間)の記事で、Facebookの「いいね!」が多かった記事をお見逃し無く。

ソーシャルもやってます!