【図解】グーグルのリンク評価20の原則【2019年版】(後編#11~#20)
グーグルが被リンクや発リンクをどう評価しているのかの最新原則20を図で解説するこの記事は、前後編の2回に分けてお届けしている。後編となる今回は、前回に引き続いて残る10個のポイントを紹介する。 →まず前編から読んでおく
- 人気が高いページからのリンクほど、強力な票になる(前編で解説)
- 独自のメインコンテンツの「中」にあるリンクは、サイト共通部分のリンクより大きな価値を引き渡す(前編で解説)
- メインコンテンツの上部にあるリンクほど、強力な票になる(前編で解説)
- 関連性の高いアンカーテキストを含むリンクは、より大きな価値を引き渡すことがある(前編で解説)
- これまでリンクしてくれたことがないドメイン名からのリンクは、すでにリンクしてくれているサイトからのリンクよりも重要だ(前編で解説)
- 他サイトからのリンクは、サイト内リンクより影響力が強い(前編で解説)
- 信頼できるシードセットからの距離が近いリンクほど、より大きな価値を引き渡すことがある(前編で解説)
- ページのトピックに関連性の高いページからのリンクは、より強力な票になることがある(前編で解説)
- 鮮度の高いページからのリンクは、鮮度の低いページからのリンクより大きな価値を引き渡し得る(前編で解説)
- リンク増加率は、鮮度のシグナルとなり得る(前編で解説)
- グーグルは、スパムリンクや低品質リンクの価値を引き下げている
- リンクエコー:リンクの影響は、リンクがなくなった後も残ることがある
- オーソリティの高いコンテンツにリンクを張っているサイトは、そうでないサイトより高く評価されることがある
- スパムページにリンクしていると、そのページからの他のリンクも、価値を下げられることがある
- nofollowリンクはフォローされないが、場合によっては価値を渡すこともある
- JavaScriptリンクの多くは価値を引き渡す――ただしグーグルがレンダリングできる場合に限る
- 1つのページ内に同じURLへのリンクが複数ある場合は、最初のリンクが優先される
- robots.txtとmeta robotsタグは、リンクの認識や取り扱いに影響を及ぼすことがある
- 否認したリンクは価値を引き渡さない(通常は)
- リンクではない言及が、データやオーソリティをウェブサイトに関連付けることがある
リンクの原則#11
グーグルは、スパムリンクや低品質リンクの価値を引き下げている
ウェブ上には膨大な数のリンクがあるが、実際のところグーグルはその大多数を無視している可能性が高い。
グーグルの目的は、エディトリアルリンク(編集リンク)に重点を置くことだ。「エディトリアルリンク」とは、リンクを受ける側のサイトでは制御できず、他のユーザーが意図して配置する独自のリンクなどを指す言葉だ。
ペンギン4.0以降、グーグルはアルゴリズムによって「これらの基準を満たしていないと思われるリンクは単に無視するだけ」だとほのめかしている。たとえば、次のようなリンクがそうした扱いを受ける:
- ネガティブSEOとして張られたリンク
- リンクプログラムで生成されたリンク
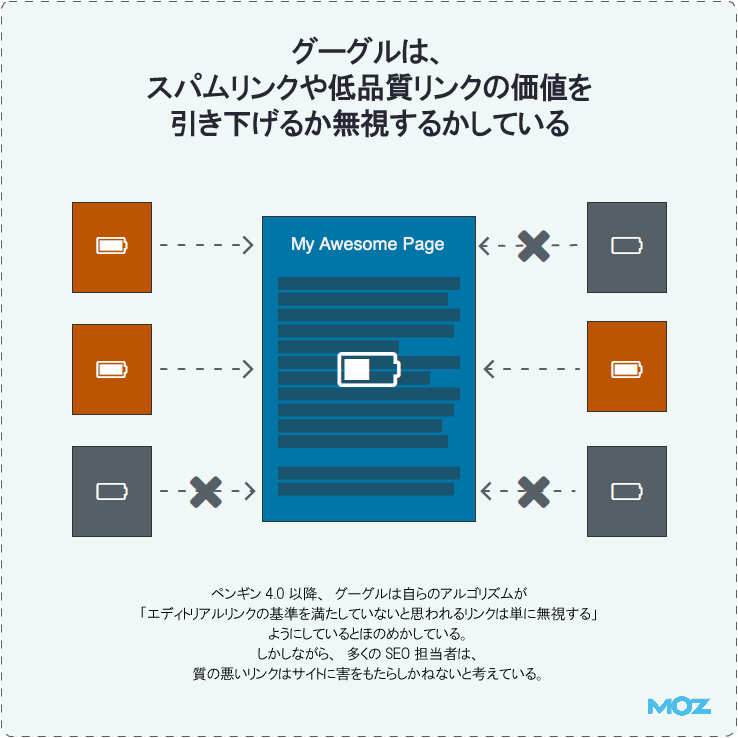
とはいえ、グーグルが本当に低品質のリンクをすべて無視しているかどうかについては、多くの議論がある。低品質のリンクが張られたサイトは実際に被害を受けかねないことが証明されているからだ(特に、操作的だとグーグルが判断する可能性のあるリンクの場合)。
リンクの原則#12
リンクエコー:リンクの影響は、リンクがなくなった後も残ることがある
「リンクエコー」(別名リンクゴースト)とは、リンクが検索順位に及ぼす影響が、リンクがなくなった後も長期間にわたって残っているように思われることが多い現象のことだ。
これについてランドがいくつか実験を行ったところ、リンクがウェブから消えて数か月が経ってもリンクの残響効果は非常に強いままで、グーグルはこれらのページを複数回にわたって再クロールし、インデックス化していた。
こうしたことが起こる理由に対する推測としては、次のようなものがある
ページの検索順位が上昇すると、グーグルが他の検索順位決定要因(ユーザーエンゲージメントなど)に目を向ける
グーグルがリンクの価値を維持するか引き下げるかの基準は、リンクがページ上にあるかどうかですべてが決まるわけではない
しかし、僕たちが明確には認識できていない要因があるのかもしれない。

根本的原因が何であれ、リンクの価値には、HTMLの記述とは別に、残響する空気のような性質がある。
これとは対照的に、「オーソリティの低いサイトが多くのリンクを一気に失った場合には、表示順位が下がった」という報告もある。ニール・パテル氏が先ごろ行った実験によるものだ。したがって、条件さえ揃えば、この現象を克服することは可能と思われる。
リンクの原則#13
オーソリティの高いコンテンツにリンクを張っているサイトは、そうでないサイトより高く評価されることがある
グーグルは、「質の高いサイトにリンクすることは、明確な検索順位決定要因ではない」としている。しかし同社は以前に、そうしたリンクが検索パフォーマンスに影響を及ぼす場合があるとコメントしたこともある。
スパムサイトや悪しき隣人にリンクしているサイトをグーグルがあまり信頼しないのと同じように、当社のシステムには、優れたサイトにリンクすることを推奨する部分がある
(マット・カッツ氏)
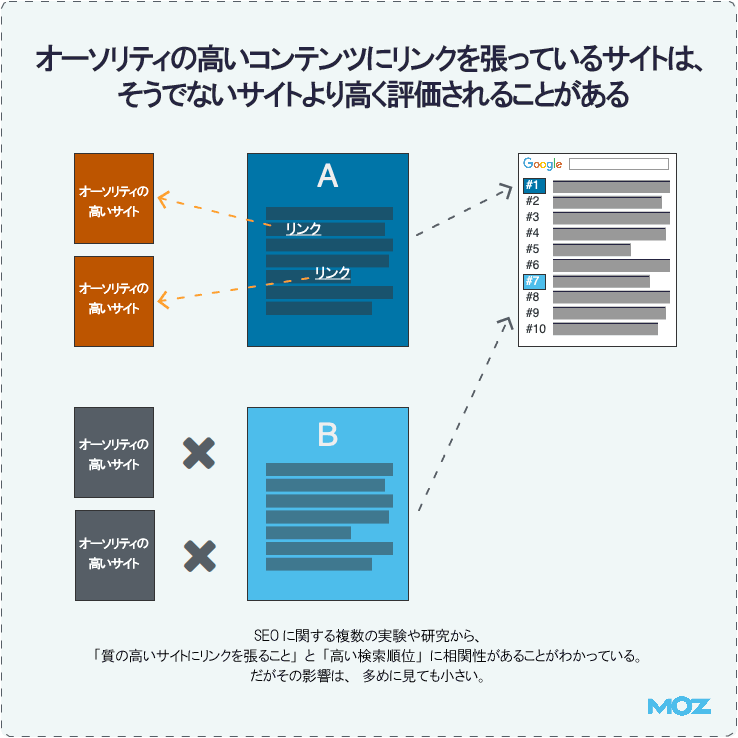
さらに、長年にわたるSEOに関する複数の実験や事例データからは、関連性もオーソリティも高いサイトにリンクすると、検索順位やビジビリティに純粋にプラスの効果があり得ることが示されている。
リンクの原則#14
スパムページにリンクしていると、そのページからの他のリンクも、価値を下げられることがある
リンクの原則#13で紹介したマット・カッツ氏の言葉で、前半部分に注目してほしい。グーグルはスパムにリンクしているサイトをあまり信頼していないことがわかる。
こういう考え方は、対象をさらに広げてみることができる。
というのも、「グーグルは、有料リンクをホストしていると見られるサイトや、プライベートブログネットワークの一部を構成していると思われるサイトの検索順位を下げている」ことを示す十分な証拠が、すでにあるからだ。
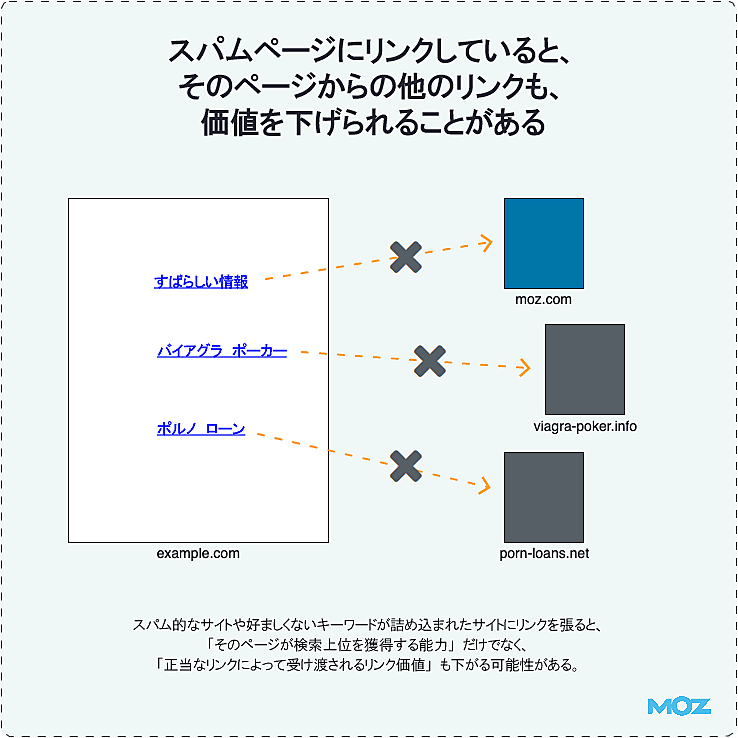
基本的なアドバイスとして、関連性が高く有益な場合は、オーディエンスのためになるのなら、オーソリティの高いサイトにリンクしよう(そして悪質なサイトにリンクするのはやめよう)。
リンクの原則#15
nofollowリンクはフォローされないが、場合によっては価値を渡すこともある
グーグルがnofollowリンクを考案したことには、大きな理由がある。特にコメントスパムやユーザー生成型コンテンツなどによって、コントロールできない外部向けスパムリンクがサイトにできるのを防ぎきれないと感じていたウェブマスターが多かったからだ。
nofollowリンクはまったく考慮されないというのが共通認識だが、グーグル自身の言葉には、いくらか曖昧な部分が残る。グーグルはnofollowリンクをまったく追跡しないわけではなく、「通常」、あくまで「原則的に」は、グーグルのウェブグラフからリンクを除外することになるという。
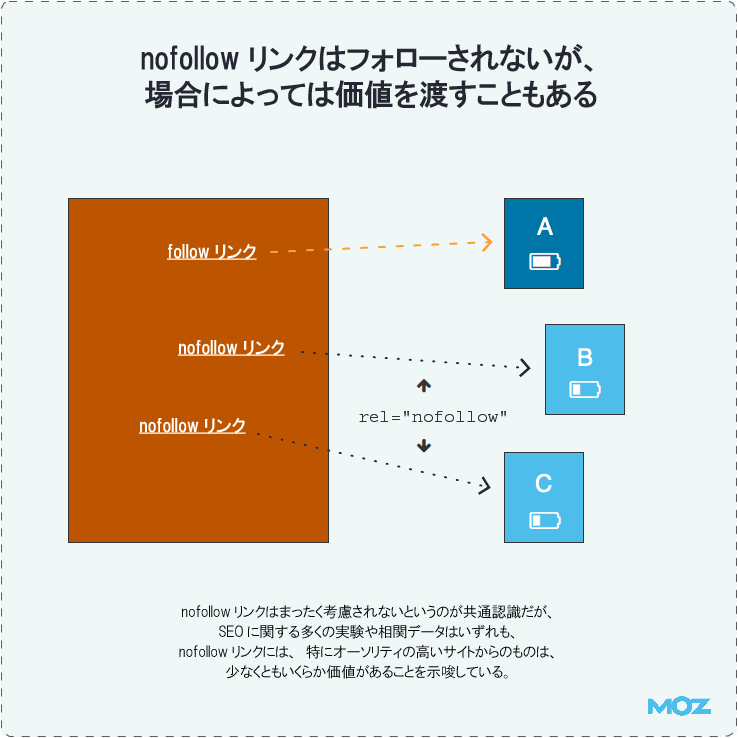
ところが、SEOに関する多くの実験や相関データはいずれも、nofollowリンクにはいくらか価値があることを示唆しているため、ウェブマスターはその価値を最大化するのが賢明だろう。
※Web担編注:グーグルはrel="nofollow"属性の指定をグーグルに対する「命令」ではなく「参考情報」として扱うように変更したことを、9月10日に発表した。ここで書かれているとおりになったわけだ。
リンクの原則#16
JavaScriptリンクの多くは価値を引き渡す――ただしグーグルがレンダリングできる場合に限る
SEOの世界ではかつて、グーグルがクロールできないことを認識したうえで、JavaScriptを使ってリンクを「隠す」手法がよく用いられていた。
今日では、グーグルがJavaScriptをクロールしてレンダリングする機能が大きく向上したため、ほとんどのJavaScriptリンクが評価対象に含まれるようになっている。
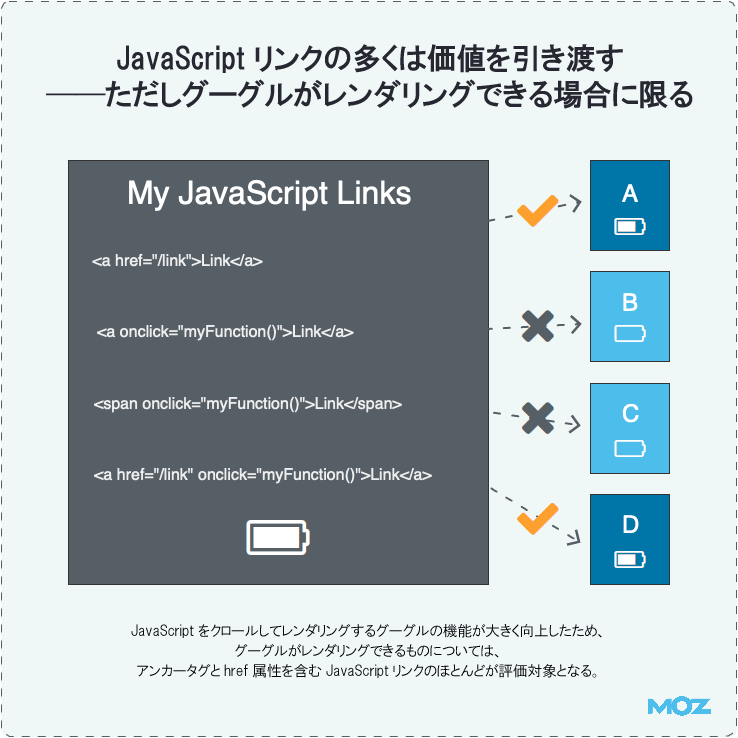
とはいえ、グーグルは現在でも、すべてのJavaScriptリンクをクロールまたはインデックス化できてはいないかもしれない。次のような理由からだ。
- グーグルがJavaScriptをレンダリングするには時間と労力が余計にかかる
- すべてのサイトが互換性のあるコードを記述しているとは限らない
加えて説明しておくと、グーグルが考慮するのは、アンカータグ(a要素)とhref属性を含む完全なリンクだけだ。つまり、クリックなどのイベントハンドラで別のページにジャンプさせる処理などはリンクとして評価されない(上図のBとCに向けた処理の部分)。
リンクの原則#17
1つのページ内に同じURLへのリンクが複数ある場合は、最初のリンクが優先される
この原則をさらに明確にしておこう。同一ページに同じURLへのリンクが複数ある場合、最初のアンカーテキストだけが考慮されるというものだ。
グーグルの説明によると、同じURLに対して張られているリンクが複数あるページをクロールした場合、PageRankはすべてのリンクを通じて通常どおりに流れるが、検索順位を決定するのに使うのは、最初のアンカーテキストだけだという。
こういう状況は、次のような場合によく起こる:
- 全体で共通のナビゲーション内から重要なページにリンクしている
- メインコンテンツ内からも、その重要なページにリンクを張っている

SEOの仲間たちはさまざまなテストを通じて、最初のリンクが優先されるルールを回避する賢い方法を数多く発見してきたが、これより新しい調査はここ数年公開されていない。
リンクの原則#18
robots.txtとmeta robotsタグは、リンクの認識や取り扱いに影響を及ぼすことがある
グーグルが独自の検索順位決定アルゴリズムでリンクの重み付けをするには、そのリンクをクロールしてリンク先を確認しなければならない。当然のことだ。
しかし、そうしたグーグルの処理を妨げる指示を、サイト全体やページ単位でする(してしまう)ことがある。例を挙げよう。
robots.txtファイル内の
Disallow指定によって、そのURLをクロールできなくなっているページの
meta robotsタグ、またはHTTPヘッダーのX-Robots-Tagで「nofollow」を指定しているページでは「
noindex, follow」を指定しているが、グーグルが最終的にリンク先までクロールするのをやめてしまう

グーグルは多くの場合、他のページからリンクされているURLを、たとえそのページがrobots.txtでブロックされていても検索結果に含める。しかし、グーグルは実際にページをクロールできないため、そのページ上のリンクはどれもグーグルからは見えないに等しい。
リンクの原則#19
否認したリンクは価値を引き渡さない(通常は)
疑わしいリンクを外部から張ってしまった場合や、ペナルティを受けてしまった場合は、グーグルが提供するリンクの否認ツールを使用すると、過ちを正す助けになる。
リンクを否認することで、グーグルはウェブをクロールする際、こうした被リンクを効果的に検討対象から外す。
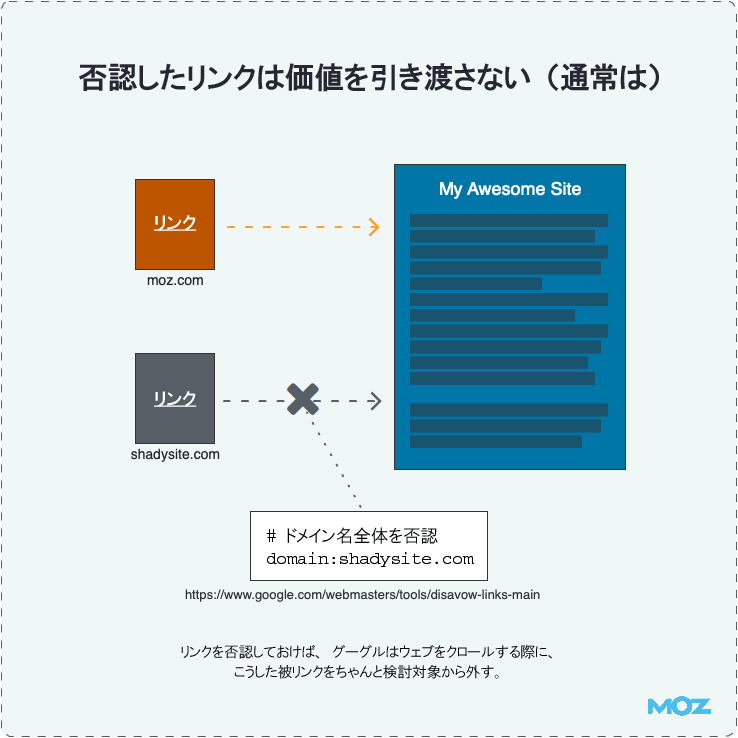
とは言うもののグーグルは、ユーザーの否認ファイルに間違いがあると判断すると、そのファイル全体を無視することがある。これはおそらく、ユーザーが自らを害することのないようにするためだろう。
リンクの原則#20
リンクではない言及が、データやオーソリティをウェブサイトに関連付けることがある
グーグルは、HTMLリンクがなくても、エンティティ(企業、人、アート作品などの概念)に関するデータをページに関連付ける場合がある。これは、ローカルビジネスにおけるサイテーション(言及、引用)の処理で行っているものと同様だ。ページ内でブランド・映画・著名人などに言及するデータがある場合も同様にしている。
これと同様にグーグルは、たとえリンクがなくても、リンクされていないメンションがデータやオーソリティをウェブサイトや一連の情報と関連付ける可能性がある。
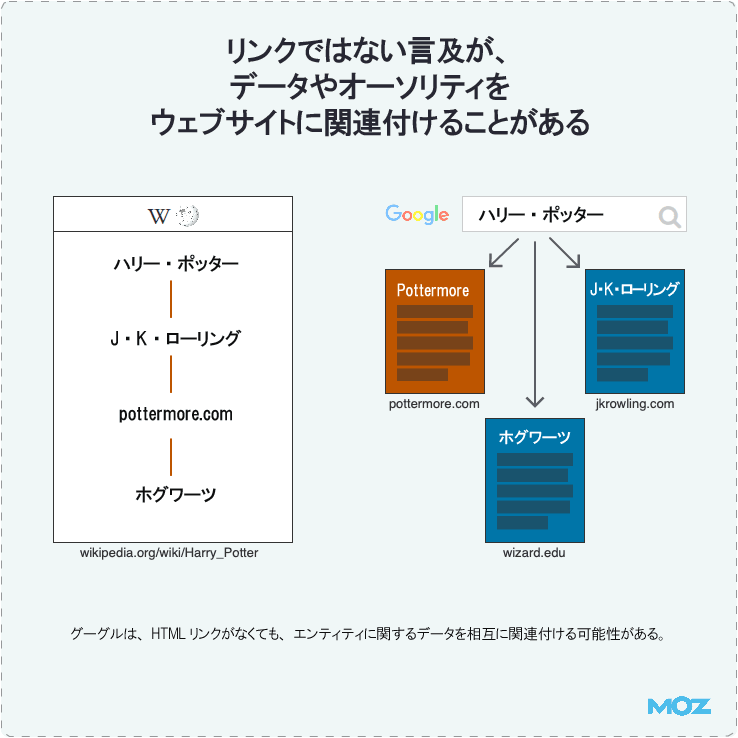
ビル・スロースキー氏は、検索におけるエンティティについてさまざまな記事を書いている(いくつか挙げると、ここと、ここと、ここにある)。これは複雑なテーマだが、次のように言えるだろう。
グーグルは、データとウェブサイトを関連付けるために必ずしもリンクを必要とするわけでない。
エンティティ間に強い関連があれば、検索結果にサイトを表示させる助けになるかもしれない。
この記事で使用したすべての画像を、高解像度でダウンロードして、顧客向けの資料やレポート、プレゼンテーション、あるいは自身のブログで使ってもらえるようにした。どの画像を使う場合も、Mozのクレジットを入れてほしい。
以下の画像では、20個すべての原則を1枚のグラフィックに組み込んでいる。

")




この記事は、Moz Blog に掲載された以下の記事を、Mozの許諾を得て日本語化したものです。

原文: 「All Links are Not Created Equal: 20 New Graphics on Google's Valuation of Links」 by Cyrus Shepard (2019/07/01)
必見! Facebookいいね! 人気記事
最近(過去90日間)の記事で、Facebookの「いいね!」が多かった記事をお見逃し無く。

ソーシャルもやってます!