ECサイトで商品詳細ページがインデックスされないときの対処方法【SEO情報まとめ】

「ECサイトで、商品詳細ページがクロールされているのにインデックスされない!」そんなあなたに、業界屈指のSEO専門家がトラブルシューティング手順をアドバイス。
ほかにも、「Google検索順位はオリジナリティ重視に?」「AIからのトラフィック、来てます!」「グーグルがURLを忘れる?」「法廷で発言、YouTubeに検索は重要ではない」などなど、今週はこのコーナーらしいSEO業界人向けのネタが多めだ。
- ECサイトで商品詳細ページがインデックスされないときの対処方法
- グーグル「2025年はオリジナリティに焦点を当てるよ!」
- 著作権年の更新くらいでサイトマップlastmodを使わないで! グーグルが注意
- 6割以上のサイトがAIからのトラフィックを獲得【3000サイトの分析から】
- SCで「URL は Google に認識されていません」としてマークされたページはクロール優先度が低いのか?
- グーグル検索からのYouTubeトラフィックはわずか1%未満!?
- グーグル検索トラフィックをLooker Studioでモニタリングする
- 多発するrobots.txtとnoindexの併用トラブル、原因はグーグル側? サイト側?
- hreflangでプロトコル相対URLを使えるか?
- SEOの最終目標は指名検索を増やすこと、ビッグキーワードでの1位ではない!
- GoogleアナリティクスとSearch Consoleのデータ乖離はなぜ発生するのか? Googleが詳しく説明
- タブに隠れたコンテンツはインデックスされたとしても悪いUX
今週のピックアップ
ECサイトで商品詳細ページがインデックスされないときの対処方法
3つの設定を確認 (Aleyda Solis on X) 海外情報
ECサイトで、商品詳細ページがクロールされているのにインデックスされない!
こんな状況のトラブルシューティング手順を、アレイダ・ソリス氏が共有してくれた(※筆者補足: ソリス氏は、スペイン出身でグローバルで活躍する業界屈指のSEOプロフェッショナル)。
まず、本当にインデックスされていないのかを再確認してください。「インデックスされていないと思っていたが、実際にはインデックスされていた」ということがよくあります(この調査は、SEOクローラーを含むさまざまなSEOツールをGoogle Search Console APIと連携させれば、まとめて実行できます)。
しかし、もしインデックス可能な状態であり、独自かつ意味のあるコンテンツが存在しているのにもかかわらず、実際にインデックスされていない場合はどうすればよいでしょうか?
※「インデックス可能な状態」とは、クロール可能であり、robots metaタグで「index, follow」が設定され、canonicalタグが正しくそのページを指定しれている状態。
「独自かつ意味のあるコンテンツ」は、タイトル、メタディスクリプション、見出し、商品説明、レビューなどが対象。
その場合、次の3つの重要な設定を確認してください:
コンテンツが正しくレンダリングされているか確認する
最新のJavaScriptフロントエンド技術を使っていてCSR(クライアントサイドレンダリング)に依存しすぎている可能性があります。レンダリングが遅すぎると、インデックスされにくくなります。
商品詳細ページのすべての独自コンテンツがインデックス可能か確認する
「レビューの一部や短縮版の説明文だけがインデックスされ、残りのコンテンツはJavaScript依存や遅延読み込み(lazy load)のため、初回のページロード時にレンダリングされていない」という状況が、多々あります。
商品詳細ページへの内部リンクが一貫して正規 URL を指しているか確認する
ナビゲーション内で、商品詳細ページへの内部リンクが正規URLを正しく指しているかをチェックしてください。異なるURLバリエーションに誤ってリンクしてしまうと、正規URLのインデックスが妨げられる可能性があります。
それでもインデックスされない場合は、インデックスされている商品詳細ページとされていない商品詳細ページのパターンを比較し、原因を特定しましょう。
ECサイト(に限らずあらゆるサイト)のウェブ担当者で、インデックスされない詳細ページが頻発しているならソリス氏のアドバイスにならって対処するといい。
Does your ecommerce suffer from an excess of "Crawled Not Indexed" PDPs? They're indexable, submitted through XML sitemaps and internally linked but somehow, not indexed? Read this. 👇
— Aleyda Solis 🕊️ (@aleyda) February 12, 2025
More often than not, due to the high number of PDPs URLs they end up being flagged to be… pic.twitter.com/TD9ZcrAn6H
- ECサイトのすべてのWeb担当者 必見!
- 技術がわかる人に伝えましょう
グーグル検索SEO情報①
グーグル「2025年はオリジナリティに焦点を当てるよ!」
独自の洞察や視点を盛り込む (Mark Williams-Cook on LinkedIn) 海外情報
Google検索では、今年は「オリジナリティ」に注力していく。それが重要になるだろう。
グーグル検索リレーションズチームのゲイリー・イリース氏が、ロンドンで開催されたSEO会合のパネルディスカッションで、上記のように発言したそうだ。
検索ランキングにおいてグーグルが、独自性のあるオリジナルコンテンツをより優先する可能性を示唆している。
コンテンツ制作者は、単なる既存情報の複製ではなく、独自の価値を提供する内容を作成する必要がある。特に生成AIツールを使用する場合、あなた自身の洞察や視点を盛り込んで、他と差別化したコンテンツを生み出すことが大切だ。
- SEOがんばってる人用(ふつうの人は気にしなくていい)
著作権年の更新くらいでサイトマップlastmodを使わないで! グーグルが注意
些細な変更で乱用するといっさい信用してもらえなくなるかも (Gary Illyes on Bluesky) 海外情報
グーグルのゲイリー・イリース氏がBlueskyで次のように注意を促した:
おいおい、みんな! ページ下部の著作権年を更新するだけでは、大きな更新とは言えない。lastmodを更新する必要はないぞ。


多くのサイトでは、ページの最下部に著作権年を掲載している。

年が明けると著作権年が(通常は自動で)更新される。しかし、これくらいの些細な更新でサイトマップのlastmodも更新して検索エンジンに送信する必要はないとイリース氏は指摘しているのだ。
lastmodは、「メインコンテンツに重要な更新が発生したときに、優先的にクロールしてもらう」ために利用する要素だ。著作権年の更新は重要度がさして高いとはいない情報だ。去年のままだったとしても、ほとんどの状況ではまったく問題にならないはずだ(そもそも、ベルヌ条約に批准している国では自動的に著作権が発生するので、著作権表記も必須ではない)。
「重要な更新」というのは、ページの大部分を変更した場合を想起しがちだが、そうとも限らない。
たとえば、ECサイトで、ある商品の価格が本当は「1500円」なのに、誤って「15000円」と表記してしまった場合は、修正後に
lastmodを使うことは理にかなっているだろう。「0」を1つ削除しただけだが、重要な変更だ。また、ページでは正しく「1500円」と表記していたが、構造化データでは誤って「15000円」と指定してしまっていた場合でも
lastmodの仕様は正当だろう。たとえ表面上は変更がなかったとしても、検索エンジンの観点(特にリッチリザルトの観点)からは重要な更新だからだ。
このように、ユーザーと検索エンジンの少なくともどちらかにとって重要な変更が発生した場合にlastmodを使う。重要とはいえない変更が発生していないにもかかわらずlastmodを乱用し続けると、グーグルはそのサイトのサイトマップを信用しなくなる可能性があるので、注意してほしい。
- ホントにSEOを極めたい人だけ
6割以上のサイトがAIからのトラフィックを獲得【3000サイトの分析から】
3強体制 (Ahrefs blog) 海外情報
Ahrefs(エイチレフス)は3,000のウェブサイトを対象としてAIチャットボットからのトラフィックを調査した。その結果、63%のサイトがAIチャットボットからのトラフィックを受け取っていることが明らかになった。ただし、全体のウェブサイト訪問者数に占める割合としては小さく、平均で0.17%にとどまっていた。
そのほか、調査のハイライトを簡潔にまとめる。
主なAI参照ソース
調査は、次の7つのチャットボットからの参照トラフィックを対象とした:
- ChatGPT
- Claude
- Copilot
- Gemini
- Perplexity
- Jasper
- Mistral
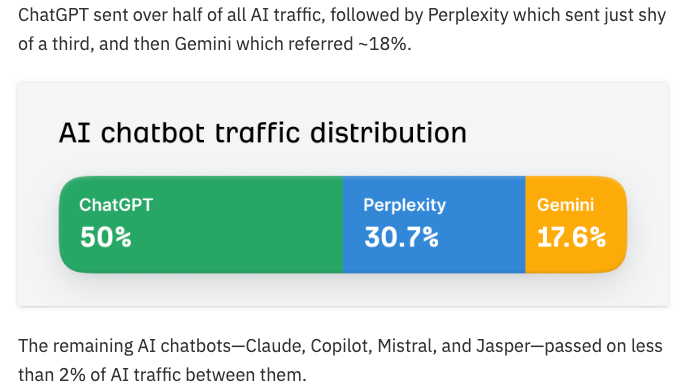
AIトラフィックの98%は、主にChatGPT、Perplexity、Geminiの3つのチャットボットから発生していた。内訳は次のようだった。
- ChatGPT ―― 50%
- Perplexity ―― 30.7%
- Gemini ―― 17.6%
3強といったところだろうか(ChatGPTが抜きん出ているが)。
ウェブサイト規模別のAIトラフィック
月間訪問者数が999未満の小規模サイトは、大規模サイトに比べてAIソースからのトラフィックの割合が相対的に高かった。また、小規模サイトではChatGPTからのAIトラフィックの割合がより大きい傾向があった。
AIトラフィックの過小評価
調査は、トラッキングの制限によりAIトラフィックが過小評価されている可能性があると指摘している。一部のAIプラットフォームはリファラー情報を渡さないため、トラフィックが「ダイレクト」として分類されることがある。これにより、AI経由のコンバージョンも過小評価される可能性があるという。
たとえば、次のようなAIプラットフォームなどがリファラーを渡していない:
- Copilot
- Mistral
- Jasper
AIトラフィック分析の活用
AIトラフィックを監視することで、次のような分析が可能だ:
- どのソースからユーザーが訪れているか
- どのページがAIトラフィックを集めているか
- AIトラフィックの変化
こうした情報を活用することで、AI参照ページやユーザーの流入経路を最適化できる。
AIトラフィックを分析するには、Ahrefs Web Analyticsを利用し、JavaScriptスニペットをサイトに追加したうえで、チャネルやソースのフィルターを設定する方法を提案している。
また、AIトラフィックのトラッキングには制限があるため、「どこで当サイトを知りましたか?」といった質問フォームなどの定性的な追跡手法を活用することも有効である。
筆者のブログの場合
調査は、プロモーションも兼ねているのか自社製ツールでの分析を紹介しているが、GA4でも、カスタマイズしたチャンネルグループを作成すればAIトラフィックを計測できる。
こちらは筆者の個人ブログの直近90日間のAIトラフィックだ。調査データでもそうだったように、全体に占める割合は微々たるものだが(それでも少しずつ増えているようにも見える)、AIチャットボットからのトラフィックは確かに発生している。
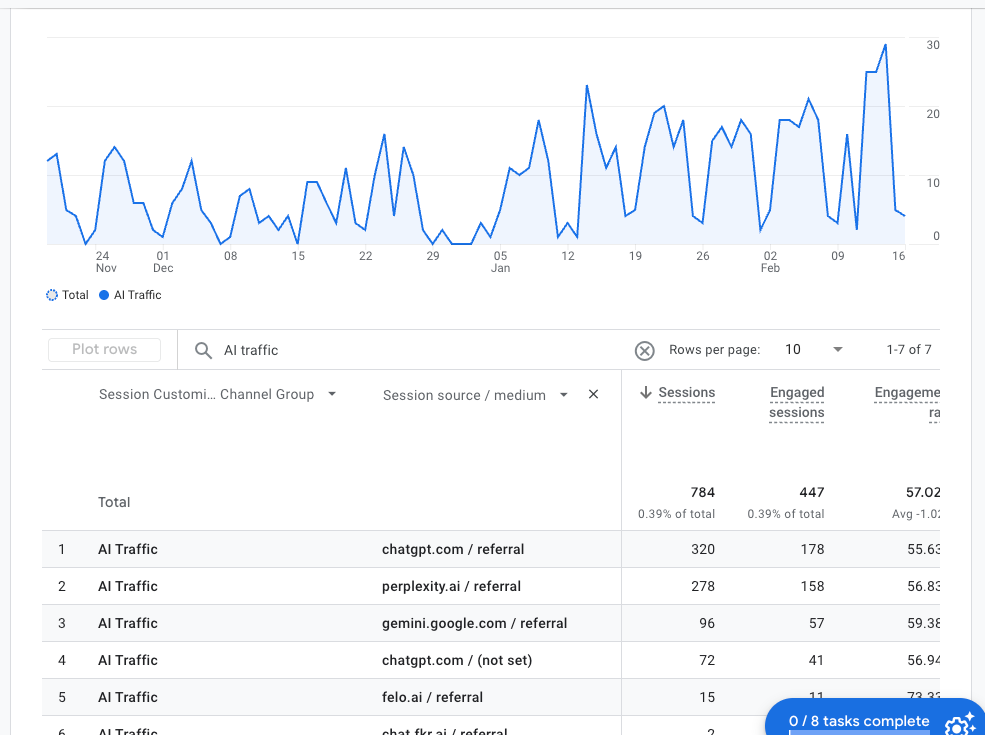
トップ3は次のとおりだ:
- ChatGPT(50%)
- Perplexity(35.5%)
- Gemini(12.2%)
カッコ内は、AIトラフィック全体に占めるパーセンテージだ。驚いたことに、順位だけでなくパーセンテージもAhrefsの調査とほぼ一致している。筆者のブログは(当然のことながら)調査データには含まれていないのだが、自分のデータを見るとAhrefsの調査の信ぴょう性は高いと感じてしまう。
今後、AIトラフィック全体のトラフィックがどのように増えていくのか、分布がどのように変化していくのかにも注目したい。検索トラフィックだけでなくAIトラフィックも本当に意識しなければならない時代が、そう遠くない将来にやってくるかもしれない。
- SEOがんばってる人用(ふつうの人は気にしなくていい)
SCで「URL は Google に認識されていません」としてマークされたページはクロール優先度が低いのか?
そもそも認識していないので優先度を割り当てていない (Gary Illyes on LinkedIn) 海外情報
Search Consoleのインデックス状態が「URL は Google に認識されていません」となっているページは、システム上でクロール優先度が最も低いと考えてよいのでしょうか?
グーグルのゲイリー・イリース氏がこんな質問を受けた。質問は次のように続く:
以前インデックスされていたページがインデックス未登録の状態になり、特に変更がない場合に最終的にこの状態になるのをよく見かけます。
インデックス済みだったページが「クロール済み - インデックス未登録」に移行するといった話がこれまでにありましたが、「URL は Google に認識されていません」という状態は、そのさらに下の段階、いわば最下層に位置するものなのか気になっています。
イリース氏は次のように回答した:
それらのURL状態は優先度を示すものではない。グーグル(検索)に認識されていないため、そもそも優先度自体が存在しない。
URLの状態は、グーグルが収集するシグナルによって変化するが、この場合、シグナルの結果としてシステムがそのURLの存在を「忘れた」状態になったということだ。
ある意味、樽の底にたどり着いたのではなく、完全に樽の外へ落ちてしまったと言えるかもしれない。
「URL は Google に認識されていません」という状態は、そのURLの存在をグーグルがもとより把握していないので、優先度をつけるもなにもないということのようだ。
認識していないのにそのURLがあることをどうしてグーグルが知っているのかという疑問が浮かぶが、サイトマップや他のサイトからのリンクによって知ったものの、自分で確かめたわけではないということだろうか。もしくは、イリース氏が言うように、以前は認識していたが現在は“忘れてしまった”という状況も発生するようだ。
忘れてしまうのは、低品質が理由の場合が多いように推測する。クロールやインデックスされない問題が低品質コンテンツ(そのページだけではなくサイト全体としても)によって引き起こされるケースは年々増えているからだ。
- SEOがんばってる人用(ふつうの人は気にしなくていい)







【執筆】

鈴木 謙一(すずき けんいち)
「海外SEO情報ブログ」の運営者。株式会社Faber Companyの執行役員(Search Advocate)。
海外SEO情報ブログは、SEOに特化した日本ではもっとも有名なSEO系ブログの1つ。米国発の最新のSEO情報を中心に、コンバージョン率アップやユーザーエクスペリエンス最適化のための施策も取り上げている。
正しいSEOをウェブ担当者に習得してもらうために、ブログでの情報発信に加えて所属先のFaber Companyでは、セミナー講師や講演スピーカーを主たる役割にしている。
必見! Facebookいいね! 人気記事
最近(過去90日間)の記事で、Facebookの「いいね!」が多かった記事をお見逃し無く。

ソーシャルもやってます!