グーグルが収集しているユーザーデータの秘密/グーグルのダークサイド?(前編)
グーグルは、何といってもデータ企業だ。グーグルはかつて、公平な競争の場で、一般に公開されているデータを競合相手よりも巧みに利用することを武器として戦った。そうすることで、空前の大成功を収めたんだ。
Web 2.0の時代に入ると、ハードディスク、プロセッサ、通信帯域、果ては労働力まで、比較的安価に入手できるようになった。そのおかげで、検索分野への参入障壁は急激に低くなった。競合相手がグーグルに追い付き始め(MSN画像検索とか)、新規参入者も現れる(Cuill)に至って、グーグルは、何らかの優位性を探し求めている。
インターネット上のコンテンツについては、誰もがほぼ対等にアクセスできるようになったから、先行している企業はあの手この手で個人データを入手しようとしている。検索エンジンにとっていちばん費用効率がいいのは、すでに自社のサービスを利用しているユーザーからデータを集めることだ。グーグルは、公開されているデータをユーザーに合わせて加工するために、ユーザーの個人データを利用している。そういうやり方で、ユーザーにとってますます役立つものになってきたんだ。このような手法は、必要な個人データがなければ真似できない。
グーグルがデータを入手するのに用いている6つの方法
クリック追跡
グーグルはすべてのサービスで、すべてのユーザーのナビゲーションに関わるすべてのクリック(広告、アクション、機能のクリックなど)を記録している。入力フォーム
ユーザーがフォームに直接入力したデータ(ユーザー名、パスワードなど)とともに、グーグルは入力した日時と場所を記録している。
 グーグルアカウントへの新規登録で使用されているコード
グーグルアカウントへの新規登録で使用されているコード- input要素のtype属性が「hidden(非表示)」になっているので、ユーザーはこのフィールド内のデータを目にしたり、そこにデータを入力したりすることはできない。
- データ送信後、ユーザーに表示されるURL(非表示)
- input要素のtype属性が「hidden」になっているので、ユーザーはこのフィールド内のデータを目にしたり、そこにデータを入力したりすることはできない。
- このフォームでは、ユーザーの参照元データが送信されるので、ユーザーがどのサービスで「登録」ボタンをクリックしたかがグーグルにわかる。
Cookie
グーグルはすべてのウェブ資産でCookieを使用している。さらに、広告(Doubleclick)用のCookieも残し、ユーザーがウェブ上をどう動き回っているかを追跡している。これにより、グーグルはDoubleclickかAdSenseの広告のあるページで、つまり、自分のウェブ資産ではないページでも、個々のユーザーを追跡できる。そういうページは膨大な数にのぼる。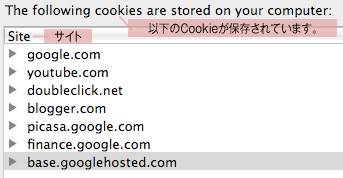 グーグルのさまざまなウェブ資産がユーザーのコンピュータに送ったCookie
グーグルのさまざまなウェブ資産がユーザーのコンピュータに送ったCookieサーバーログファイルに保存されているサーバーリクエスト
グーグルのサーバーに送られたリクエストは、ログファイルに保存される。保存される内容はリクエストのタイプによって違う。 ログファイルの例
ログファイルの例URL - "http://www.google.com/search?hl=en&q=seomoz&ie=UTF-8"
- リクエストを送ったユーザーのIPアドレス。これからユーザーの居場所がわかる
- ユーザーがリクエストを出した日時や時間帯
- リクエストされた検索結果の表示言語(この場合は英語)
- 検索クエリ
- ユーザーのOS
- ユーザーのブラウザ
JavaScript
グーグルは、インターネット上のグーグル関連サイトに小さなJavaScriptを仕込んでいる。ユーザーのブラウザはバックグラウンドでそのスクリプトを自動的に実行し、グーグルは、ユーザー個人のインターネット利用動向(居場所、オペレーティングシステム、ブラウザの種類やバージョンなど)について重要な情報を得られる。ウェブビーコン
グーグルは小さな(1×1ピクセルの)透過GIFファイルを、確認画面や操作完了画面の多くに埋め込んでいる。JavaScriptと同じように、ブラウザはその目に見えない画像を自動的にダウンロードし、その際にコンピュータに関する情報がグーグルに送信される。
グーグルはデータを何に使っているのか
保存
グーグルはBigTableという、100万台近いサーバーに分散した独自のデータベースを使っている。グーグルが保管しているデータ量(2006年)データ サイズ(単位:テラバイト) 検索インデックス 800 Google Analytics 200 Google Base 2 Google Earth 70 Orkut 9 パーソナライズド検索 4 これは、テラバイト単位(1テラバイト=1024ギガバイト)で表した圧縮済みデータのサイズだ。グーグルがここで明らかにしているデータのサイズは合計1ペタバイト(100万ギガバイト)を超えている。こいつぁすげえや!
ここには、AdSenseやGmail、グーグルマップ、ストリートビュー、グーグルイメージ検索といった非公開のデータベースは入っていない。今やそのデータ量は膨大なものになっていると考えられる。何しろこの数字は、Web 2.0によってデータが急増し始める以前の2年前の統計からとったものだからね。
大量データの解析
これはちょっと「チャーリーとチョコレート工場」みたいな話だ。データが大量にグーグルに渡っていて、そこから加工された便利なデータが出てきているは周知のとおり。その途中がどうなっているのかはわからない。グーグルには、自分が持つデータを並べ替えて整理するアルゴリズムがたくさんあることも知られている。中でも有名なのはPageRankだ。その上、複雑なスパムフィルタや、重複コンテンツフィルタ、パターン検出アルゴリズム、自然言語解析、画像認識ソフトウェア、その他複雑なソフトウェアが多数ある。
恒久的なバックアップ
グーグルが取ったデータが最終的に行き着く先は恒久的ストレージらしい。グーグルのプライバシーポリシーを読むと、この恒久的なバックアップがあるために、一部のユーザーデータは完全に削除されることがないことがわかる。

グーグルがどんな風にユーザーのデータを集めているのかわかっただろうか。次回は、グーグルがユーザーから集めているデータの全リストを公開する。→後編を読む

")



この記事は、Daily SEOmoz Blog に掲載された以下の記事を日本語訳したものです。
原文:「The Evil Side of Google? Exploring Google's User Data Collection」 by Danny Dover (2008/06/24 18:00 PDT)
必見! Facebookいいね! 人気記事
最近(過去90日間)の記事で、Facebookの「いいね!」が多かった記事をお見逃し無く。

ソーシャルもやってます!