「売れるクッキー」と「売れてないクッキー」のデータ分析で熊本名産のクッキー開発に挑む
データ分析によって導き出したエビデンスを活用したマーケティングを提唱する、データビークルの油野氏は、「デジタルマーケターズサミット 2019 Summer」に登壇。同社が提供する拡張アナリティクス「dataDiver」を活用して、どのようにデータから新商品のクッキーを開発したか解説した。

データから新商品のクッキーを開発した事例
今回、油野氏が支援することになったのは、阿蘇郡南阿蘇村にあるお菓子メーカーの「古今堂」。「復興への起爆剤として、全国で勝負できるクッキーを作りたい」との同社社長の思いを受ける形で、新商品開発のプロジェクトが開始された。
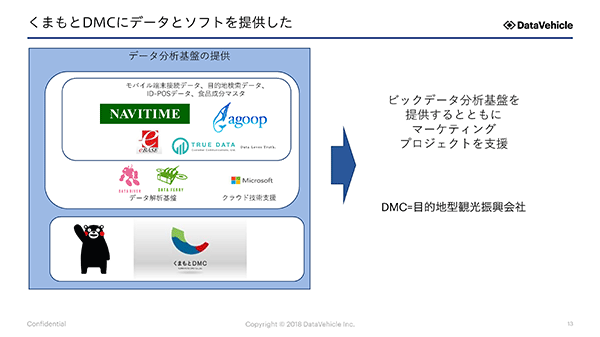
このプロジェクトは、2016年に起こった熊本地震の復興を加速させるために2017年に設立された「くまもとDMC※」の支援プログラムの一環である。
DMC(Destination Management Company)とは、観光庁が力を入れている政策の一つで、地域の自然や食などの観光資源を使って、地域と協力して観光業の発展を支援する法人組織のこと。
くまもとDMCは「データサイエンスに基づくリサーチデザインを自社で行うこと」をコンセプトに設立された、同社の支援者としてデータビークルの油野氏は参加している。
売れるクッキーと売れないクッキーの差って?
新商品開発にあたり、「売れるクッキー」と「売れてないクッキー」の差は何かを調べるために、油野氏はまずデータ分析から始めることにした。
しかし、2017年に設立されたばかりの「くまもとDMC」には、十分なデータが社内になかった。そこで、モバイル端末接続データ、目的地検索データ、ID-POSデータ、食品成分マスターデータといった外部データを集めて、データ分析することにした。
「売れているクッキー」と「売れていないクッキー」の差
油野氏は、クッキーの原材料の違いから調べることにした。分析を進めるなかで最初にわかったことは、売れているクッキーには「チョコチップ」と「ココナッツ」が入っていることだった。
しかし、この2つを使用したクッキーではありきたりと考え、もう少し分析を続けたところ、売れているクッキーには、「豚肉由来の成分」が入っていることもわかった。

「豚肉由来の成分の有無は、発見かもしれない!」とプロジェクトで報告した油野氏。
しかし、古今堂からは「豚肉由来の成分は、サクサクした食感を出すために使われている成分で、別名「ショートニング」と呼ばれている。ショートニングは安価であるため、さまざまなな加工食品に含まれるが、その成分に含まれるトランス脂肪酸が健康被害を引き起こす可能性が指摘されている成分だ」との返答があったという。
「データ分析から得られた知見が、現場で本当に知りたいことと違う」ということは、データ分析の現場でよくあることだと油野氏は指摘する。
つまり、売れているクッキーは、一般的に1箱100円程度の価格帯が多く、その価格帯の傾向値を分析した油野氏だったが、現場で本当に知りたかったのは、定番価格帯と高価な価格帯の差だったのだ。
高価格のクッキーとはいくらか?
そこで、「高価格のクッキー」という切り口を再挑戦のヒントに活かし、再調査を実施。価格帯を調査し、高価格とは1箱「200円以上300円未満」、超高価格が「300円以上」であることがわかった。
そして、「200円以上300円未満」のクッキーの中で売れているものとそうでないものの差を分析したところ、以下の2つの発見を得た。
- 「いちご」「キャラメル」「ごま」の成分を含む場合に売れ筋の傾向がある
- 賞味期限が「270日以上365日未満」の場合に売れ筋の傾向がある
熊本の特産物がいちごとオレンジ(柑橘系)であることを踏まえると、徐々に製品の構想が見えてきた。
この発見を活かしてできた製品が、熊本が開発したいちごの新品種「ゆうべに」を使った「ゆうべにCOOKIES」である。2019年の春に発売開始し、現在は空港や県下の土産物店で入手できる。

データ分析のプロ、データサイエンティストはコストが高い
このように、データ分析を意思決定に活かした商品開発や施策に役立てる「データドリブンマーケティング」を実践するしようとする企業は多い。
データ分析をするといえば、データサイエンティストが欠かせない。しかし、統計知識があり、PythonやRを自由に使えるデータサイエンティストが人材不足だ。また、国内で社外のデータサイエンティストに仕事を頼もうとすると、1人当たり月額400万円が相場でコストがかかる。
さらに、外部のデータサイエンティストを活用して、プロジェクトを遂行する場合、プロジェクトを進める前に、データサイエンティストに自社の業務内容を理解してもらう必要がある。つまり、人材費用の他に、コミュニケーションコストがかかるのだ。それならば社内で育成したいと考え、データサイエンティスト講座に人を派遣するが、学べるのはスキルのみ。
しかも、データサイエンティストは月額給与の相場が150~200万円なので、スキルを得たらすぐに転職されるという悪循環に陥っている。
データサイエンティストはマーケター脳ではない
データサイエンティストの代わりとして、注目されている機能が「拡張アナリティクス」だ。今回、油野氏が説明した「くまもとDMC」のプロジェクトは、まさに拡張アナリティクスを使ってプロジェクトが進行した。
では、一体拡張アナリティクスとはどういったことか?
簡単に言えば、「現場が必要とする打ち手を見つけるためのインサイト」を提供する機能だ。
たとえば、「リピート顧客を増やしたい」という目的に対して、拡張アナリティクスでは、「リピートした人」と「リピートしなかった人」の差を見つけ(図1)、そこから次の打ち手を考えるといった具合だ。

上記例の場合、「リピートした人」と「リピートしなかった人」を「年齢層」「居住地」「買ったもの」「買った時期」「来店方法」「同伴者」などの膨大なデータから差を見つけて、施策を考えていけるわけだ。
また、2019年5月にガートナーが発表した「2019年のデータ/アナリティクス・テクノロジー・トレンドのトップ10」では、「機械学習(ML)とAIの手法を用いて、分析対象となるコンテンツの開発、利用、共有方法を変革するもの」としている。
データの前処理も重要
講演の終盤、油野氏はデータ分析の前に行う前処理の重要性についても触れた。データ分析をしたいと考える会社でよく見られるのが「宝の山がゴミの山」だったというケースである。
まず、レシートには経営者が知りたいことは書かれていない。たとえば、最近「低カロリー」のカレールウが売れているから、どのぐらい売れているかを調べてみることにしたとしよう。しかし、レシートには商品名はあっても、カロリーについての情報は印刷されていない。
では売り上げ伝票はどうか。ある取扱商品が女性のバイヤーからの評価が高いので、女性バイヤーをターゲットにアプローチしようと考えた。しかし、売り上げ伝票のデータを見ると、宛て先には名字しかなく、性別は当然わからない。請求に関係がないので、詳細が入力されていないのだ。
分析に必要なデータが含まれなかったり、抜け漏れがあったり、全角と半角が混在していて汚れていたりするデータはゴミでしかない。
分析できるデータを整えることとは、分析前の基本である。データ分析とは、意思決定の岐路に立たされたときに、進むべき方向を教えてくれるものであると述べ、講演を終えた。




必見! Facebookいいね! 人気記事
最近(過去90日間)の記事で、Facebookの「いいね!」が多かった記事をお見逃し無く。


ソーシャルもやってます!